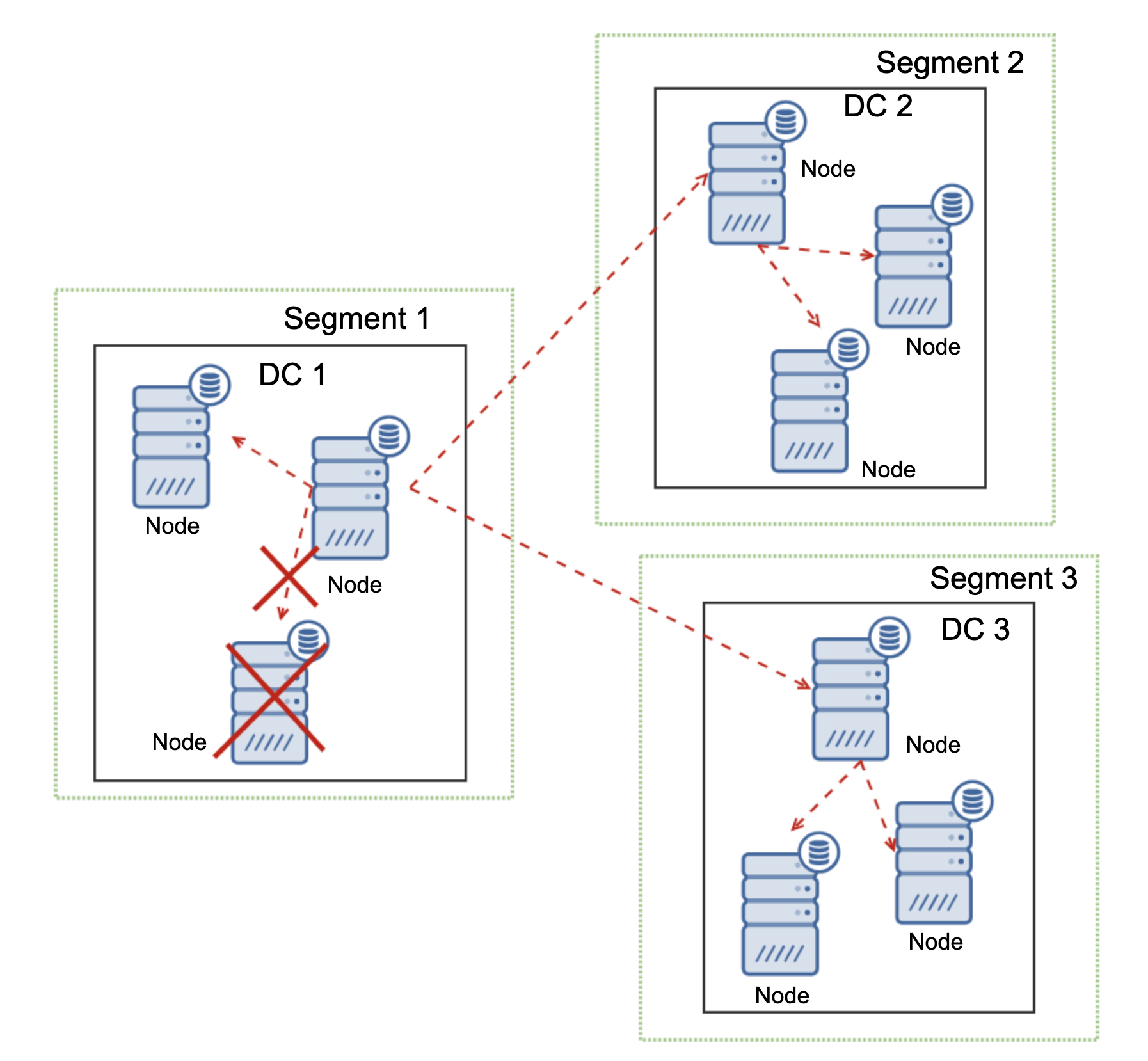
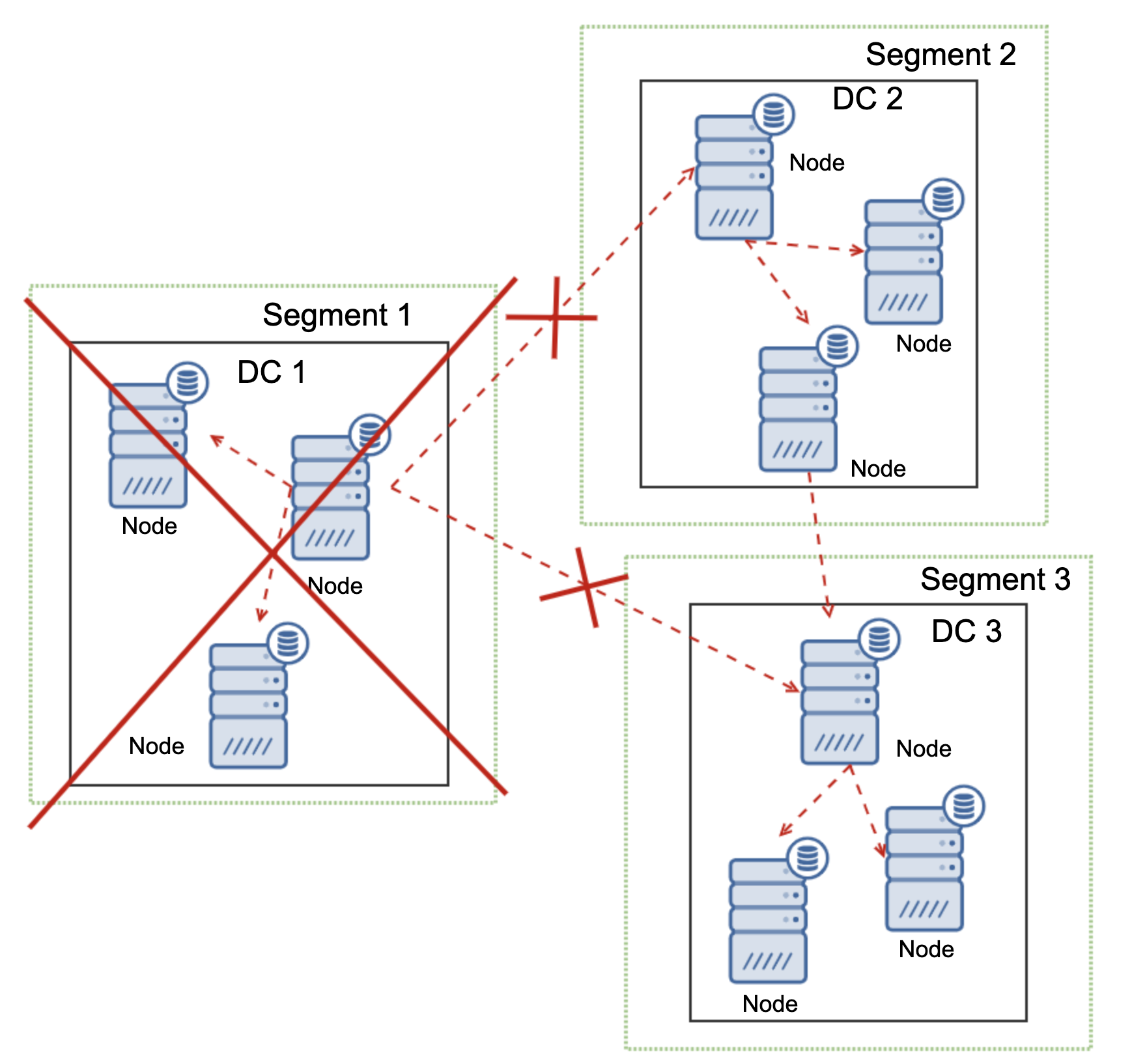
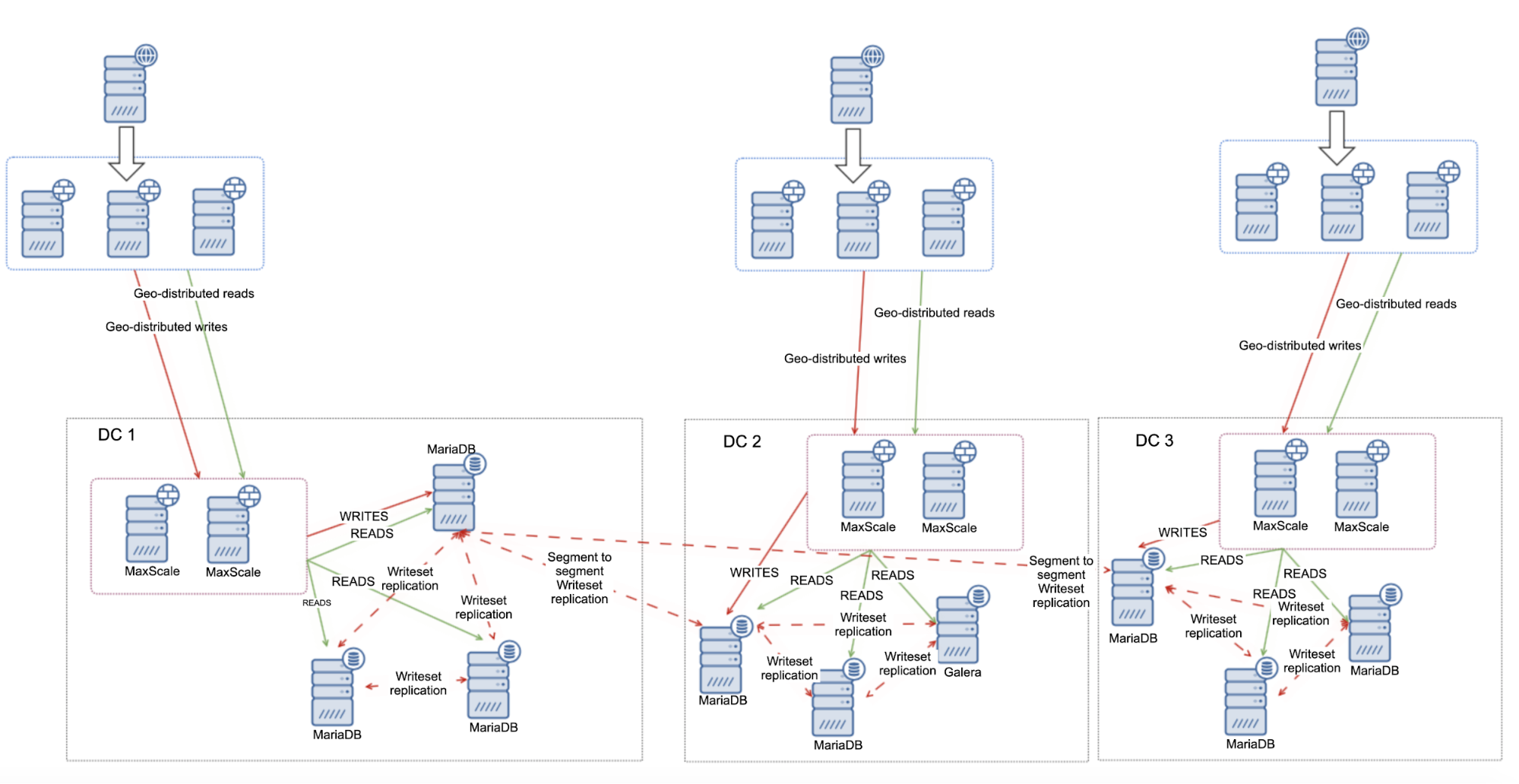
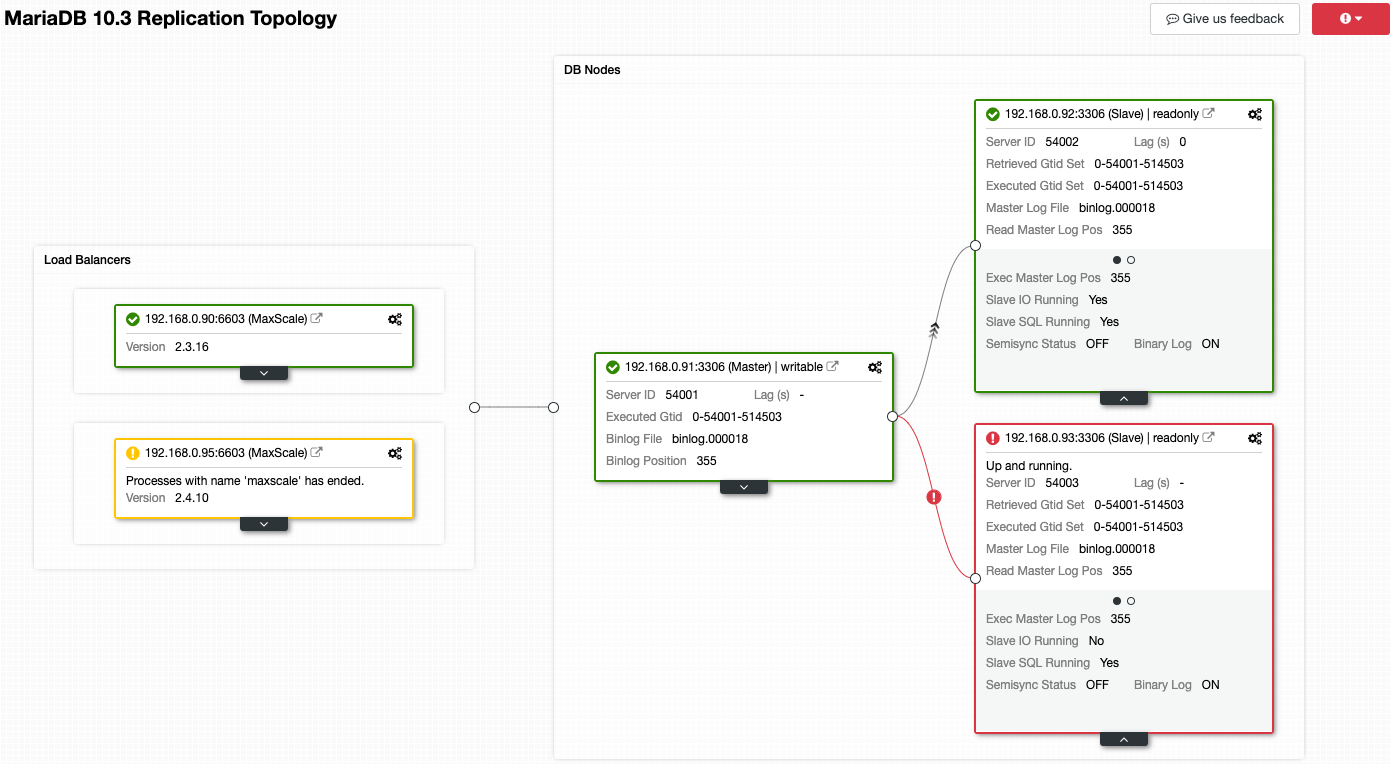
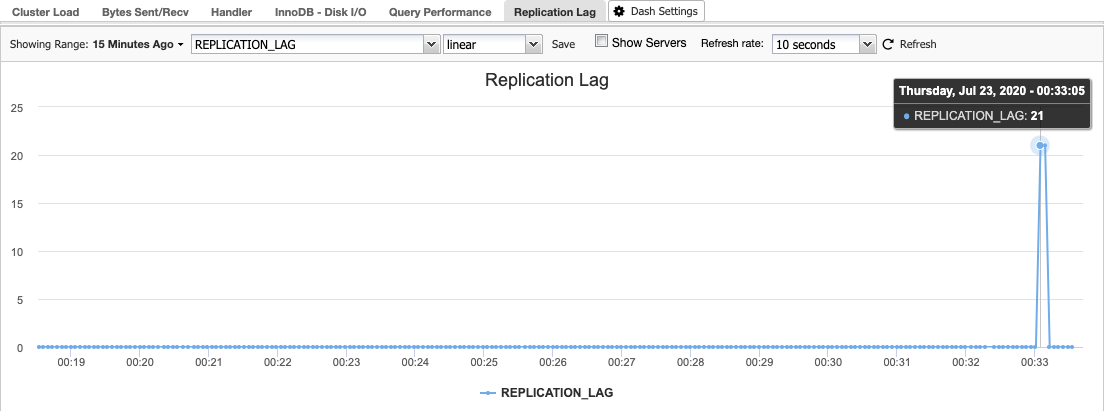
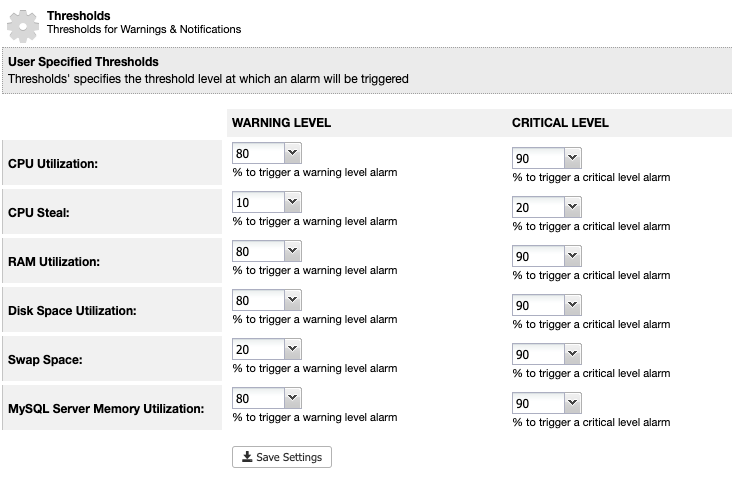
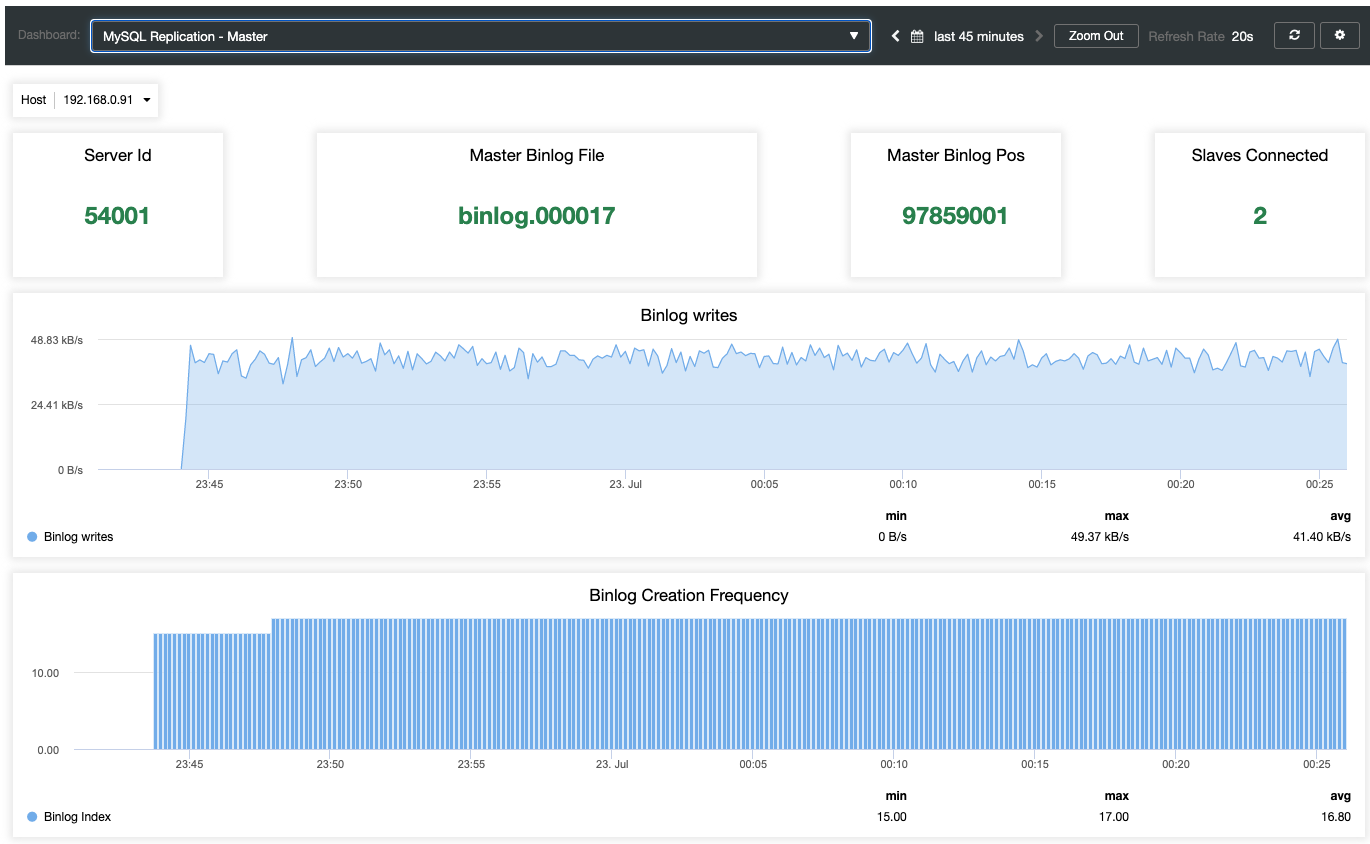
In the previous blog post, we have covered some introductions to MaxScale installation, upgrade, and deployment using MaxCtrl command-line client. In this blog post, we are going to cover the MaxScale management aspects for our MariaDB Cluster.
There are a number of MaxScale components that we can manage with MaxCtrl, namely:
- Server management
- Service management
- Monitor management
- Listener management
- Filter management
- MaxScale management
- Logging management
In this blog post, we are going to cover the first 4 components which are commonly used in MariaDB Cluster. All of the commands in this blog post are based on MaxScale 2.4.11.
Server Management
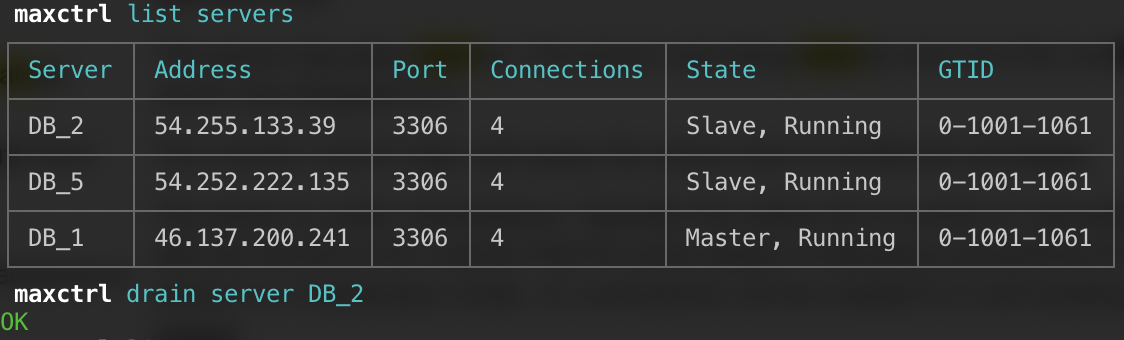
List/Show Servers
List a summary of all servers in MaxScale:
maxctrl: list servers
┌────────────────┬────────────────┬──────┬─────────────┬─────────────────────────┬─────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera1 │ 192.168.10.201 │ 3306 │ 0 │ Slave, Synced, Running │ 100-100-203 │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera2 │ 192.168.10.202 │ 3306 │ 0 │ Slave, Synced, Running │ 100-100-203 │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera3 │ 192.168.10.203 │ 3306 │ 0 │ Master, Synced, Running │ 100-100-203 │
└────────────────┴────────────────┴──────┴─────────────┴─────────────────────────┴─────────────┘
For MariaDB Cluster, the server list summarizes the node and cluster state, with its MariaDB GTID, only if the cluster is set to replicate from another cluster via the standard MariaDB Replication. The state is used by MaxScale to control the behavior of the routing algorithm:
- Master - For a Cluster, this is considered the Write-Master.
- Slave - If all slaves are down, but the master is still available, then the router will use the master.
- Synced - A Cluster node which is in a synced state with the cluster.
- Running - A server that is up and running. All servers that MariaDB MaxScale can connect to are labeled as running.
Although MariaDB Cluster is capable of handling multi-master replication, MaxScale will always pick one node to hold the Master role which will receive all writes for readwritesplit routing. By default, the Galera Monitor will choose the node with the lowest wsrep_local_index value as the master. This will mean that two MaxScales running on different servers will choose the same server as the master.
Show all servers in more detail:
maxctrl: show servers
Create Servers
This is commonly the first thing you need to do when setting up MaxScale as a load balancer. It's common to add all of the MariaDB Cluster nodes into MaxScale and label it with an object name. In this example, we label the Galera nodes as in "mariadbgalera#" format:
maxctrl: create server mariadbgalera1 192.168.0.221 3306
maxctrl: create server mariadbgalera2 192.168.0.222 3306
maxctrl: create server mariadbgalera3 192.168.0.222 3306
The server state will only be reported correctly after we have activated the monitoring module, as shown under the Monitor Management section further down.
Delete a Server
To delete a server, one has to unlink the server from any services or monitors beforehand. As an example, in the following server list, we would want to delete mariadbgalera3 from MaxScale:
maxctrl: list servers
┌────────────────┬────────────────┬──────┬─────────────┬─────────────────────────┬─────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera1 │ 192.168.10.201 │ 3306 │ 0 │ Slave, Synced, Running │ 100-100-203 │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera2 │ 192.168.10.202 │ 3306 │ 0 │ Slave, Synced, Running │ 100-100-203 │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼─────────────┤
│ mariadbgalera3 │ 192.168.10.203 │ 3306 │ 0 │ Master, Synced, Running │ 100-100-203 │
└────────────────┴────────────────┴──────┴─────────────┴─────────────────────────┴─────────────┘
List out all monitors and see if the server is part of any monitor module:
maxctrl: list monitors
┌─────────────────┬─────────┬────────────────────────────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────┼─────────┼────────────────────────────────────────────────┤
│ MariaDB-Monitor │ Running │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
└─────────────────┴─────────┴────────────────────────────────────────────────┘
Looks like mariadbgalera3 is part of MariaDB-Monitor, so we have to remove it first by using the "unlink monitor" command:
maxctrl: unlink monitor MariaDB-Monitor mariadbgalera3
OK
Next, list out all services to check if the corresponding server is part of any MaxScale services:
maxctrl: list services
┌─────────────────────┬────────────────┬─────────────┬───────────────────┬────────────────────────────────────────────────┐
│ Service │ Router │ Connections │ Total Connections │ Servers │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Read-Write-Service │ readwritesplit │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Round-Robin-Service │ readconnroute │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Replication-Service │ binlogrouter │ 1 │ 1 │ │
└─────────────────────┴────────────────┴─────────────┴───────────────────┴────────────────────────────────────────────────┘
As you can see, mariadbgalera3 is part of the Read-Write-Service and Round-Robin-Service. Remove the server from those services by using "unlink service" command:
maxctrl: unlink service Read-Write-Service mariadbgalera3
OK
maxctrl: unlink service Round-Robin-Service mariadbgalera3
OK
Finally, we can remove the server from MaxScale by using the "destroy server" command:
maxctrl: destroy server mariadbgalera3
OK
Verify using the "list servers" that we have removed mariadbgalera3 from MaxScale.:
maxctrl: list servers
┌────────────────┬────────────────┬──────┬─────────────┬─────────────────────────┬──────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼──────┤
│ mariadbgalera1 │ 192.168.10.201 │ 3306 │ 0 │ Master, Synced, Running │ │
├────────────────┼────────────────┼──────┼─────────────┼─────────────────────────┼──────┤
│ mariadbgalera2 │ 192.168.10.202 │ 3306 │ 0 │ Slave, Synced, Running │ │
└────────────────┴────────────────┴──────┴─────────────┴─────────────────────────┴──────┘
Modify Server's Parameter
To modify a server's parameter, one can use the "alter server" command which only takes one key/value parameter at a time. For example:
maxctrl: alter server mariadbgalera3 priority 10
OK
Use the "show server" command and look into the Parameters section, for a list of parameters that can be changed for the "server" object:
maxctrl: show server mariadbgalera3
...
│ Parameters │ { │
│ │ "address": "192.168.10.203", │
│ │ "protocol": "mariadbbackend", │
│ │ "port": 3306, │
│ │ "extra_port": 0, │
│ │ "authenticator": null, │
│ │ "monitoruser": null, │
│ │ "monitorpw": null, │
│ │ "persistpoolmax": 0, │
│ │ "persistmaxtime": 0, │
│ │ "proxy_protocol": false, │
│ │ "ssl": "false", │
│ │ "ssl_cert": null, │
│ │ "ssl_key": null, │
│ │ "ssl_ca_cert": null, │
│ │ "ssl_version": "MAX", │
│ │ "ssl_cert_verify_depth": 9, │
│ │ "ssl_verify_peer_certificate": false, │
│ │ "disk_space_threshold": null, │
│ │ "priority": "10"│
│ │ }
Note that alter command effect is immediate and the parameter's value in the runtime will be modified as well as the value in its individual MaxScale configuration file inside /var/lib/maxscale/maxscale.cnf.d/ for persistence across restart.
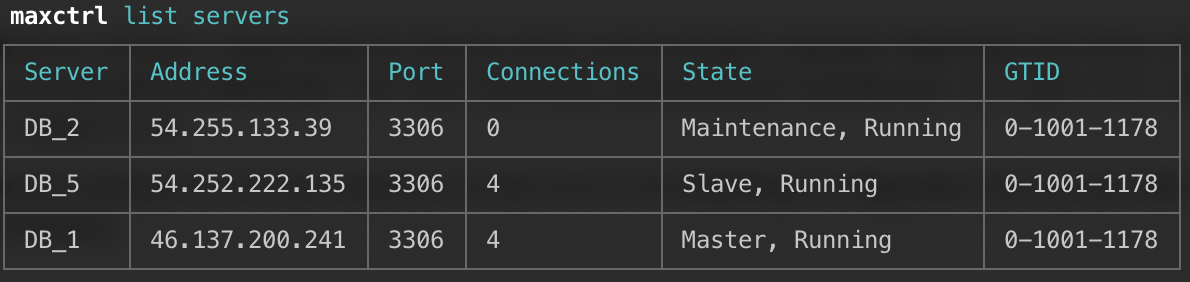
Set Server State
MaxScale allows the backend Galera servers to be temporarily excluded from the load balancing set by activating the maintenance mode. We can achieve this by using the "set server" command:
maxctrl: set server mariadbgalera3 maintenance
OK
When looking at the state of the server, we should see this:
maxctrl: show server mariadbgalera3
...
│ State │ Maintenance, Running
...
When a server is in maintenance mode, no connections will be created to it and existing connections will be closed. To clear the maintenance state from the host, use the "clear server" command:
maxctrl: clear server mariadbgalera3 maintenance
OK
Verify with "show server":
maxctrl: show server mariadbgalera3
...
│ State │ Slave, Synced, Running │
...
Monitor Management
Create a Monitor
The MaxScale monitor module for MariaDB Cluster is called galeramon. Defining a correct monitoring module is necessary so MaxScale can determine the best routing for queries depending on the state of the nodes. For example, if a Galera node is serving as a donor for a joiner node, should it be part of the healthy nodes? In some cases like where the database size is so small, marking a donor node as healthy (by setting the parameter available_when_donor=true in MaxScale) is not a bad plan and sometimes improves the query routing performance.
To create a service (router), one must create a monitoring user on the backend of MariaDB servers. Commonly, one would use the same monitoring user that we have defined for the monitor module. For Galera Cluster, if the monitoring user does not exist, just create it on one of the nodes with the following privileges:
MariaDB> CREATE USER maxscale_monitor@'192.168.0.220' IDENTIFIED BY 'MaXSc4LeP4ss';
MariaDB> GRANT SELECT ON mysql.* TO 'maxscale_monitor'@'192.168.0.220';
MariaDB> GRANT SHOW DATABASES ON *.* TO 'maxscale_monitor'@'192.168.0.220';
Use the "create monitor" command and specify a name with galeramon as the monitor module:
maxctrl: create monitor MariaDB-Monitor galeramon servers=mariadbgalera1,mariadbgalera2,mariadbgalera3 user=maxscale_monitor password=MaXSc4LeP4ss
OK
Note that we didn't configure MaxScale secret which means we store the user password in plain text format. To enable encryption, see the example in this blog post, Introduction to MaxScale Administration Using maxctrl for MariaDB Cluster under Adding Monitoring into MaxScale section.
List/Show Monitors
To list out all monitors:
maxctrl: list monitors
┌─────────────────┬─────────┬────────────────────────────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────┼─────────┼────────────────────────────────────────────────┤
│ MariaDB-Monitor │ Running │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
└─────────────────┴─────────┴────────────────────────────────────────────────┘
To get a more detailed look on the monitor, use the "show monitor" command:
maxctrl: show monitor MariaDB-Monitor
┌─────────────────────┬───────────────────────────────────────────┐
│ Monitor │ MariaDB-Monitor │
├─────────────────────┼───────────────────────────────────────────┤
│ State │ Running │
├─────────────────────┼───────────────────────────────────────────┤
│ Servers │ mariadbgalera1 │
│ │ mariadbgalera2 │
│ │ mariadbgalera3 │
├─────────────────────┼───────────────────────────────────────────┤
│ Parameters │ { │
│ │ "user": "maxscale_monitor", │
│ │ "password": "*****", │
│ │ "passwd": null, │
│ │ "monitor_interval": 2000, │
│ │ "backend_connect_timeout": 3, │
│ │ "backend_read_timeout": 1, │
│ │ "backend_write_timeout": 2, │
│ │ "backend_connect_attempts": 1, │
│ │ "journal_max_age": 28800, │
│ │ "disk_space_threshold": null, │
│ │ "disk_space_check_interval": 0, │
│ │ "script": null, │
│ │ "script_timeout": 90, │
│ │ "events": "all", │
│ │ "disable_master_failback": false, │
│ │ "available_when_donor": true, │
│ │ "disable_master_role_setting": false, │
│ │ "root_node_as_master": false, │
│ │ "use_priority": false, │
│ │ "set_donor_nodes": false │
│ │ } │
├─────────────────────┼───────────────────────────────────────────┤
│ Monitor Diagnostics │ { │
│ │ "disable_master_failback": false, │
│ │ "disable_master_role_setting": false, │
│ │ "root_node_as_master": false, │
│ │ "use_priority": false, │
│ │ "set_donor_nodes": false │
│ │ } │
└─────────────────────┴───────────────────────────────────────────┘
Stop/Start Monitor
Stopping a monitor will pause the monitoring of the servers. This commonly being used in conjunction with "set server" command to manually control server states. To stop the monitoring service use the "stop monitor" command:
maxctrl: stop monitor MariaDB-Monitor
OK
Verify the state with "show monitor":
maxctrl: show monitors MariaDB-Monitor
┌─────────────────────┬───────────────────────────────────────────┐
│ Monitor │ MariaDB-Monitor │
├─────────────────────┼───────────────────────────────────────────┤
│ State │ Stopped │
...
To start it up again, use the "start monitor":
maxctrl: start monitor MariaDB-Monitor
OK
Modify Monitor's Parameter
To change a parameter for this monitor, use the "alter monitor" command and specify the parameter key/value as below:
maxctrl: alter monitor MariaDB-Monitor available_when_donor true
OK
Use the "show monitor" command and look into the Parameters section, for a list of parameters that can be changed for the galeramon module:
maxctrl: show server mariadbgalera3
...
│ Parameters │ { │
│ │ "user": "maxscale_monitor", │
│ │ "password": "*****", │
│ │ "monitor_interval": 2000, │
│ │ "backend_connect_timeout": 3, │
│ │ "backend_read_timeout": 1, │
│ │ "backend_write_timeout": 2, │
│ │ "backend_connect_attempts": 1, │
│ │ "journal_max_age": 28800, │
│ │ "disk_space_threshold": null, │
│ │ "disk_space_check_interval": 0, │
│ │ "script": null, │
│ │ "script_timeout": 90, │
│ │ "events": "all", │
│ │ "disable_master_failback": false, │
│ │ "available_when_donor": true, │
│ │ "disable_master_role_setting": false, │
│ │ "root_node_as_master": false, │
│ │ "use_priority": false, │
│ │ "set_donor_nodes": false │
│ │ } │
Delete a Monitor
In order to delete a monitor, one has to remove all servers linked with the monitor first. For example, consider the following monitor in MaxScale:
maxctrl: list monitors
┌─────────────────┬─────────┬────────────────────────────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────┼─────────┼────────────────────────────────────────────────┤
│ MariaDB-Monitor │ Running │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
└─────────────────┴─────────┴────────────────────────────────────────────────┘
Remove all servers from that particular service:
maxctrl: unlink monitor MariaDB-Monitor mariadbgalera1 mariadbgalera2 mariadbgalera3
OK
Our monitor is now looking like this:
maxctrl: list monitors
┌─────────────────┬─────────┬─────────┐
│ Monitor │ State │ Servers │
├─────────────────┼─────────┼─────────┤
│ MariaDB-Monitor │ Running │ │
└─────────────────┴─────────┴─────────┘
Only then we can delete the monitor:
maxctrl: destroy monitor MariaDB-Monitor
OK
Add/Remove Servers into Monitor
After creating a monitor, we can use the "link monitor" command to add the Galera servers into the monitor. Use the server's name as created under Create Servers section:
maxctrl: link monitor MariaDB-Monitor mariadbgalera1 mariadbgalera2 mariadbgalera3
OK
Similarly, to remove a server from the service, just use "unlink monitor" command:
maxctrl: unlink monitor MariaDB-Monitor mariadbgalera3
OK
Verify with "list monitors" or "show monitors" command.
Service Management
Create a Service
To create a service (router), one must create a monitoring user on the backend of MariaDB servers. Commonly, one would use the same monitoring user that we have defined for the monitor module. For Galera Cluster, if the monitoring user does not exist, just create it on one of the nodes with the following privileges:
MariaDB> CREATE USER maxscale_monitor@'192.168.0.220' IDENTIFIED BY 'MaXSc4LeP4ss';
MariaDB> GRANT SELECT ON mysql.* TO 'maxscale_monitor'@'192.168.0.220';
MariaDB> GRANT SHOW DATABASES ON *.* TO 'maxscale_monitor'@'192.168.0.220';
Where 192.168.0.220 is the IP address of the MaxScale host.
Then, specify the name of the service, the routing type together with a monitoring user for MaxScale to connect to the backend servers:
maxctrl: create service Round-Robin-Service readconnroute user=maxscale_monitor password=******
OK
Also, you can specify additional parameters when creating the service. In this example, we would like the "master" node to be included in the round-robin balancing set for our MariaDB Galera Cluster:
maxctrl: create service Round-Robin-Service readconnroute user=maxscale_monitor password=****** router_options=master,slave
OK
Use the "show service" command to see the supported parameters. For round-robin router, the list as follows:
maxctrl: show service Round-Robin-Service
...
│ Parameters │ { │
│ │ "router_options": null, │
│ │ "user": "maxscale_monitor", │
│ │ "password": "*****", │
│ │ "passwd": null, │
│ │ "enable_root_user": false, │
│ │ "max_retry_interval": 3600, │
│ │ "max_connections": 0, │
│ │ "connection_timeout": 0, │
│ │ "auth_all_servers": false, │
│ │ "strip_db_esc": true, │
│ │ "localhost_match_wildcard_host": true, │
│ │ "version_string": null, │
│ │ "weightby": null, │
│ │ "log_auth_warnings": true, │
│ │ "retry_on_failure": true, │
│ │ "session_track_trx_state": false, │
│ │ "retain_last_statements": -1, │
│ │ "session_trace": 0
For the read-write split router, the supported parameters are:
maxctrl: show service Read-Write-Service
...
│ Parameters │ { │
│ │ "router_options": null, │
│ │ "user": "maxscale_monitor", │
│ │ "password": "*****", │
│ │ "passwd": null, │
│ │ "enable_root_user": false, │
│ │ "max_retry_interval": 3600, │
│ │ "max_connections": 0, │
│ │ "connection_timeout": 0, │
│ │ "auth_all_servers": false, │
│ │ "strip_db_esc": true, │
│ │ "localhost_match_wildcard_host": true, │
│ │ "version_string": null, │
│ │ "weightby": null, │
│ │ "log_auth_warnings": true, │
│ │ "retry_on_failure": true, │
│ │ "session_track_trx_state": false, │
│ │ "retain_last_statements": -1, │
│ │ "session_trace": 0, │
│ │ "use_sql_variables_in": "all", │
│ │ "slave_selection_criteria": "LEAST_CURRENT_OPERATIONS", │
│ │ "master_failure_mode": "fail_instantly", │
│ │ "max_slave_replication_lag": -1, │
│ │ "max_slave_connections": "255", │
│ │ "retry_failed_reads": true, │
│ │ "prune_sescmd_history": false, │
│ │ "disable_sescmd_history": false, │
│ │ "max_sescmd_history": 50, │
│ │ "strict_multi_stmt": false, │
│ │ "strict_sp_calls": false, │
│ │ "master_accept_reads": false, │
│ │ "connection_keepalive": 300, │
│ │ "causal_reads": false, │
│ │ "causal_reads_timeout": "10", │
│ │ "master_reconnection": false, │
│ │ "delayed_retry": false, │
│ │ "delayed_retry_timeout": 10, │
│ │ "transaction_replay": false, │
│ │ "transaction_replay_max_size": "1Mi", │
│ │ "optimistic_trx": false │
│ │ }
List/Show Services
To list out all created services (routers), use the "list services" command:
maxctrl: list services
┌─────────────────────┬────────────────┬─────────────┬───────────────────┬────────────────────────────────────────────────┐
│ Service │ Router │ Connections │ Total Connections │ Servers │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Read-Write-Service │ readwritesplit │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Round-Robin-Service │ readconnroute │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Binlog-Repl-Service │ binlogrouter │ 1 │ 1 │ │
└─────────────────────┴────────────────┴─────────────┴───────────────────┴────────────────────────────────────────────────┘
In the above examples, we have created 3 services, with 3 different routers. However, the Binlog-Repl-Service for our binlog server is not linked with any servers yet.
To show all services in details:
maxctrl: show services
Or if you want to show a particular service:
maxctrl: show service Round-Robin-Service
Stop/Start Services
Stopping a service will prevent all the listeners for that service from accepting new connections. Existing connections will still be handled normally until they are closed. To stop and start all services, use the "stop services":
maxctrl: stop services
maxctrl: show services
maxctrl: start services
maxctrl: show services
Or we can use the "stop service" to stop only one particular service:
maxctrl: stop services Round-Robin-Service
Delete a Service
In order to delete a service, one has to remove all servers and destroy the listeners associated with the service first. For example, consider the following services in MaxScale:
maxctrl: list services
┌─────────────────────┬────────────────┬─────────────┬───────────────────┬────────────────────────────────────────────────┐
│ Service │ Router │ Connections │ Total Connections │ Servers │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Read-Write-Service │ readwritesplit │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Round-Robin-Service │ readconnroute │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Replication-Service │ binlogrouter │ 1 │ 1 │ │
└─────────────────────┴────────────────┴─────────────┴───────────────────┴────────────────────────────────────────────────┘
Let's remove Round-Robin-Service from the setup. Remove all servers from this particular service:
maxctrl: unlink service Round-Robin-Service mariadbgalera1 mariadbgalera2 mariadbgalera3
OK
Our services are now looking like this:
maxctrl: list services
┌─────────────────────┬────────────────┬─────────────┬───────────────────┬────────────────────────────────────────────────┐
│ Service │ Router │ Connections │ Total Connections │ Servers │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Read-Write-Service │ readwritesplit │ 1 │ 1 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Round-Robin-Service │ readconnroute │ 1 │ 1 │ │
├─────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Replication-Service │ binlogrouter │ 1 │ 1 │ │
└─────────────────────┴────────────────┴─────────────┴───────────────────┴────────────────────────────────────────────────┘
If the service is tied with a listener, we have to remove it as well. Use "list listeners" and specify the service name to look for it:
maxctrl: list listeners Round-Robin-Service
┌──────────────────────┬──────┬─────────┬─────────┐
│ Name │ Port │ Host │ State │
├──────────────────────┼──────┼─────────┼─────────┤
│ Round-Robin-Listener │ 3307 │ 0.0.0.0 │ Running │
└──────────────────────┴──────┴─────────┴─────────┘
And then remove the listener:
maxctrl: destroy listener Round-Robin-Service Round-Robin-Listener
OK
Finally, we can remove the service:
maxctrl: destroy service Round-Robin-Service
OK
Modify Service's Parameter
Similar to the other object, one can modify a service parameter by using the "alter service" command:
maxctrl: alter service Read-Write-Service master_accept_reads true
OK
Some routers support runtime configuration changes to all parameters. Currently all readconnroute, readwritesplit and schemarouter parameters can be changed at runtime. In addition to module specific parameters, the following list of common service parameters can be altered at runtime:
- user
- passwd
- enable_root_user
- max_connections
- connection_timeout
- auth_all_servers
- optimize_wildcard
- strip_db_esc
- localhost_match_wildcard_host
- max_slave_connections
- max_slave_replication_lag
- retain_last_statements
Note that alter command effect is immediate and the parameter's value in the runtime will be modified as well as the value in its individual MaxScale configuration file inside /var/lib/maxscale/maxscale.cnf.d/ for persistence across restart.
Add/Remove Servers into Service
After creating a service, we can use the link command to add our servers into the service. Use the server's name as created under Create Servers section:
maxctrl: link service Round-Robin-Service mariadbgalera1 mariadbgalera2 mariadbgalera3
OK
Similarly, to remove a server from the service, just use "unlink service" command:
maxctrl: unlink service Round-Robin-Service mariadbgalera3
OK
We can only remove one server from a service at a time, so repeat it for other nodes to delete them. Verify with "list services" or "show services" command.
Listener Management
List Listeners
To list all listeners, we need to know the service name in advanced:
maxctrl: list services
┌──────────────────────┬────────────────┬─────────────┬───────────────────┬────────────────────────────────────────────────┐
│ Service │ Router │ Connections │ Total Connections │ Servers │
├──────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Read-Write-Service │ readwritesplit │ 0 │ 0 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├──────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
│ Round-Robin-Service │ readconnroute │ 0 │ 0 │ mariadbgalera1, mariadbgalera2, mariadbgalera3 │
├──────────────────────┼────────────────┼─────────────┼───────────────────┼────────────────────────────────────────────────┤
In the above example, we have two services, Read-Write-Service and Round-Robin-Service. Then, we can list out the listener for that particular service. For Read-Write-Service:
maxctrl: list listeners Read-Write-Service
┌─────────────────────┬──────┬─────────┬─────────┐
│ Name │ Port │ Host │ State │
├─────────────────────┼──────┼─────────┼─────────┤
│ Read-Write-Listener │ 3306 │ 0.0.0.0 │ Running │
└─────────────────────┴──────┴─────────┴─────────┘
And for Round-Robin-Service:
maxctrl: list listeners Round-Robin-Service
┌──────────────────────┬──────┬─────────┬─────────┐
│ Name │ Port │ Host │ State │
├──────────────────────┼──────┼─────────┼─────────┤
│ Round-Robin-Listener │ 3307 │ 0.0.0.0 │ Running │
└──────────────────────┴──────┴─────────┴─────────┘
Unlike other objects in MaxScale, the listener does not have a "show" and "alter" commands since it is a fairly simple object.
Create a Listener
Make sure a service has been created. In this example, taken from the Create Service section above, we will create a listener so MaxScale will listen on port 3307 to process the MariaDB connections in a round-robin fashion:
maxctrl: create listener Round-Robin-Service Round-Robin-Listener 3307
OK
Delete a Listener
To delete a listener, use the "destroy listener" command with the respective service name and listener name:
maxctrl: destroy listener Round-Robin-Service Round-Robin-Listener
OK
This concludes this episode of basic MaxScale management tasks for MariaDB Cluster. In the next series, we are going to cover the MaxScale advanced management tasks like service filters, MaxScale user management and so on.