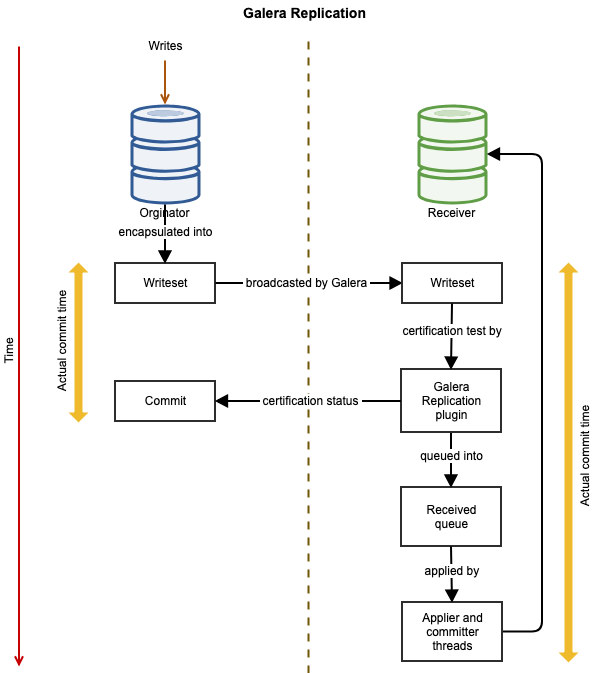
In previous blogs, we discussed the topic of How to Migrate from Oracle to MySQL / Percona Server and most recently Migrating from Oracle Database to MariaDB - What You Should Know.
Over the years and as new versions of MySQL and MariaDB were released, both projects have deviated entirely into two very different RDBMS platforms.
MariaDB and MySQL now diverge from each other significantly, especially with the arrival of their most recent versions: MySQL 8.0 and MariaDB 10.3 GA and its 10.4 (currently RC candidate).
With the release MariaDB TX 3.0, MariaDB surprised many since it is no longer a drop-in replacement for MySQL. It introduces a new level of compatibility with Oracle database and is now becoming a real alternative to Oracle as well as other enterprise and proprietary databases such as IBM DB2 or EnterpriseDB.
Starting with MariaDB version 10.3, significant features have been introduced such as system-versioned tables and, what's most appealing for Oracle DBA's, support for PL/SQL!
According to the MariaDB website, approximately 80% of the legacy Oracle PL/SQL can be migrated without rewriting the code. MariaDB also has ColumnStore, which is their new analytics engine and a columnar storage engine designed for distributed, massively parallel processing (MPP), such as for big data analytics.
The MariaDB team have worked hard for the added support for PL/SQL. It adds extra ease when migrating to MariaDB from Oracle. As a reference point for your planned migration, you can check the following reference from MariaDB. As per our previous blog, this will not cover the overall process of migration, as it is a long process. But it will hopefully provide enough background information to serve as a guide for your migration process.
Planning and Development Strategy
For the DBA, migrating from Oracle database going to MariaDB, such a migration means a lot of similar factors that shouldn’t be too difficult to shift and adapt to. MariaDB can be operated in Windows server and does have binaries available for Windows platform for downloads. If you are using Oracle for OLAP (Online Analytical Processing) or business intelligence, MariaDB also has the ColumnStore, which is the equivalent of Oracle's Database In-Memory column store.
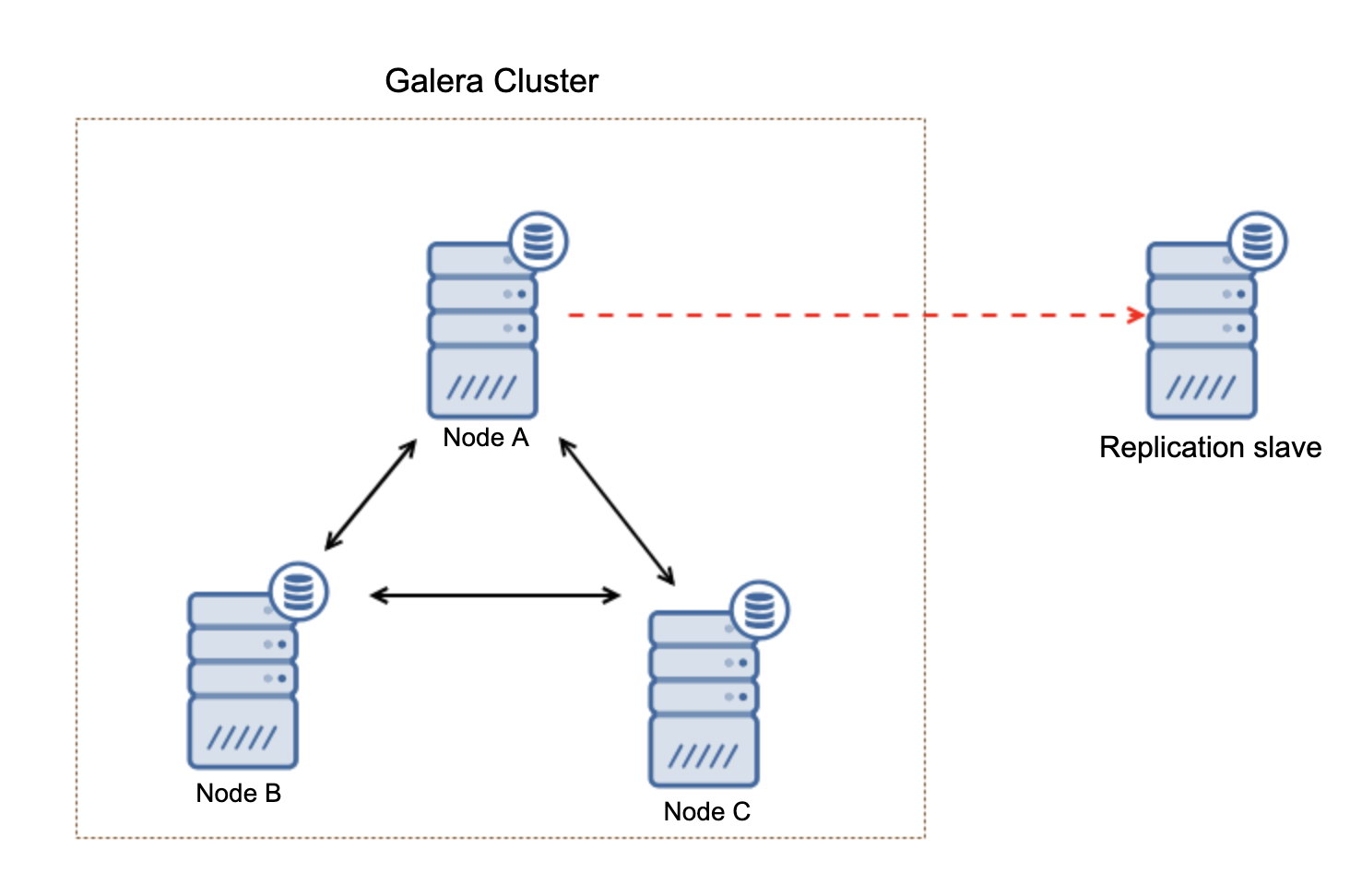
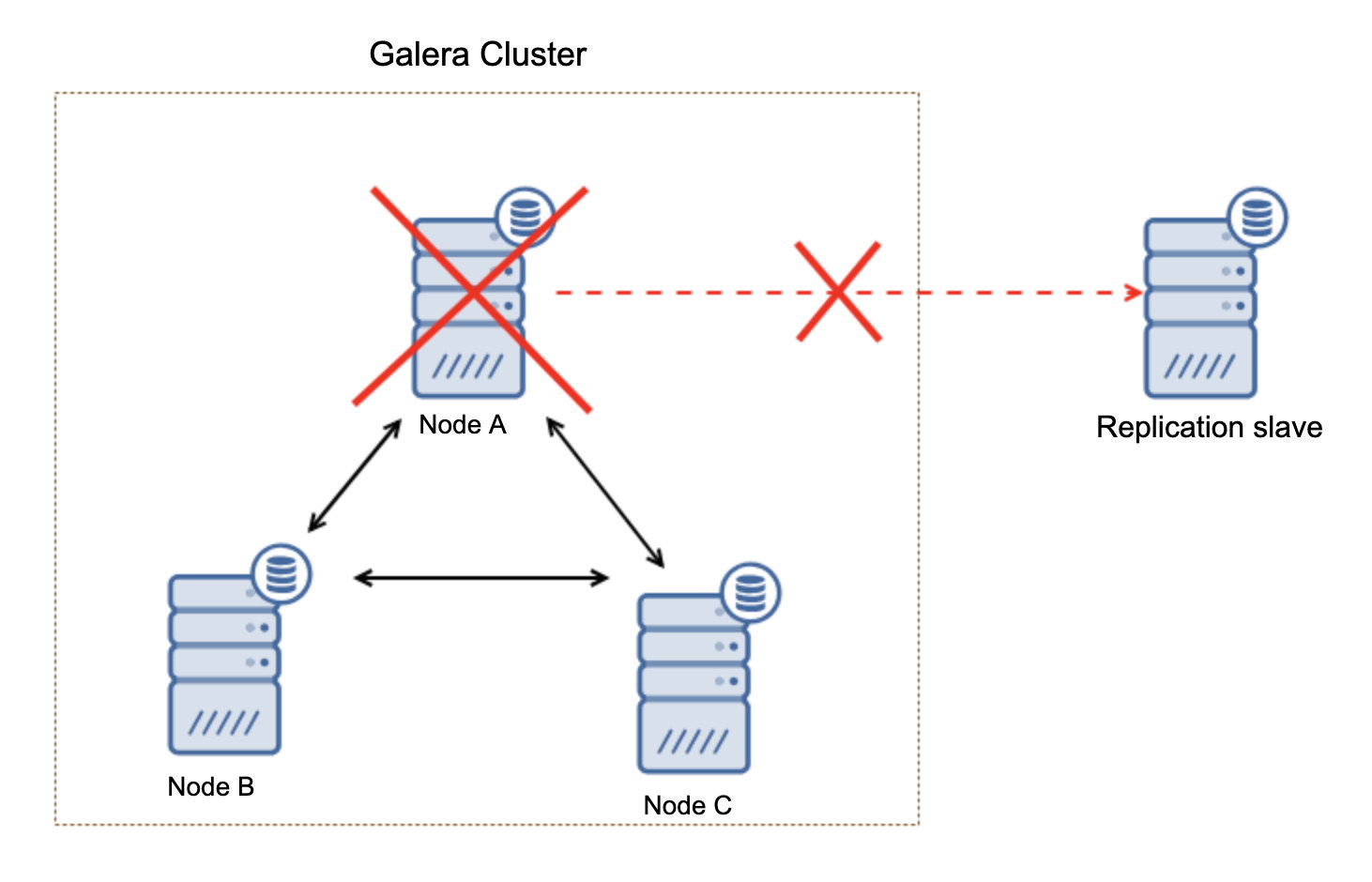
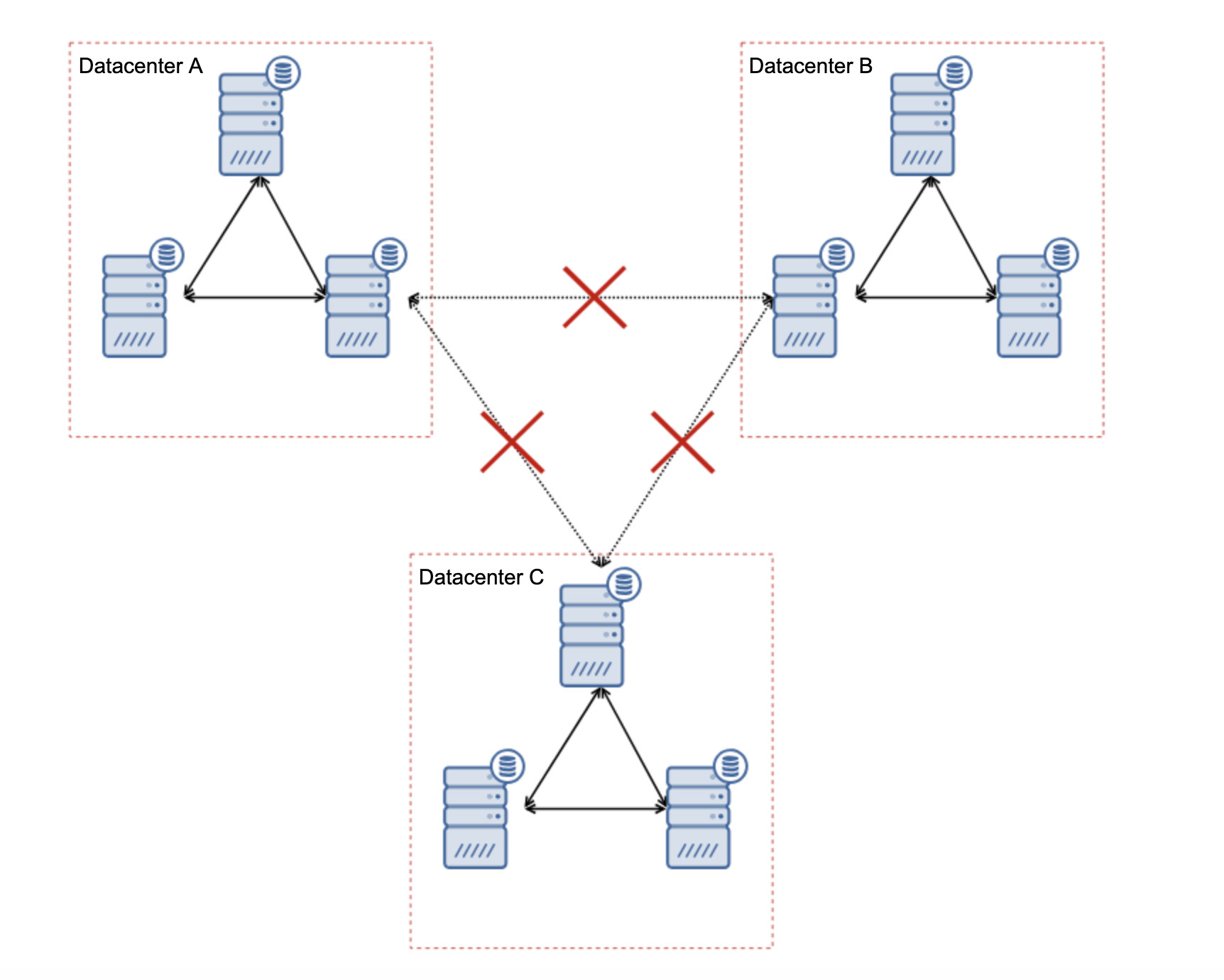
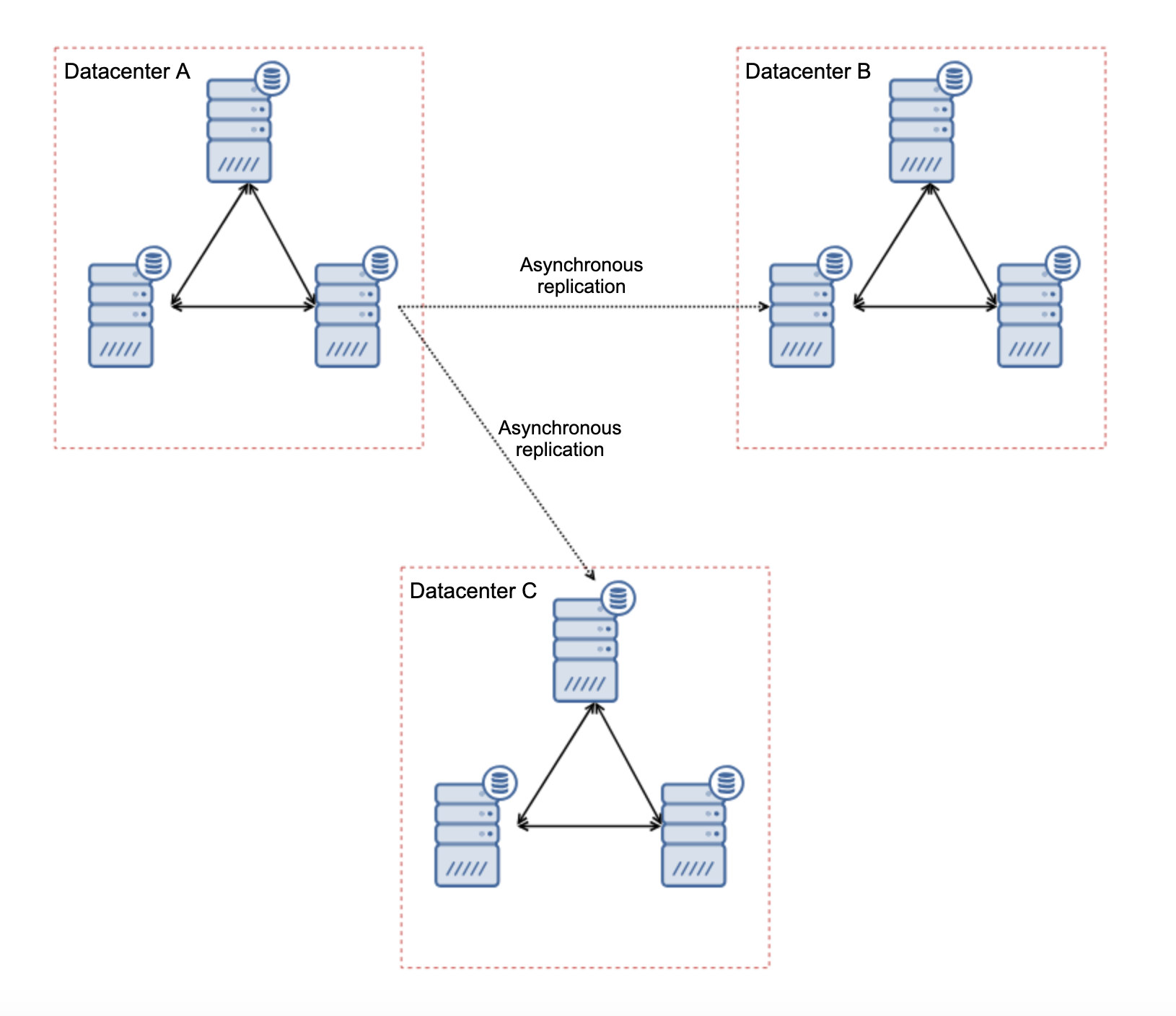
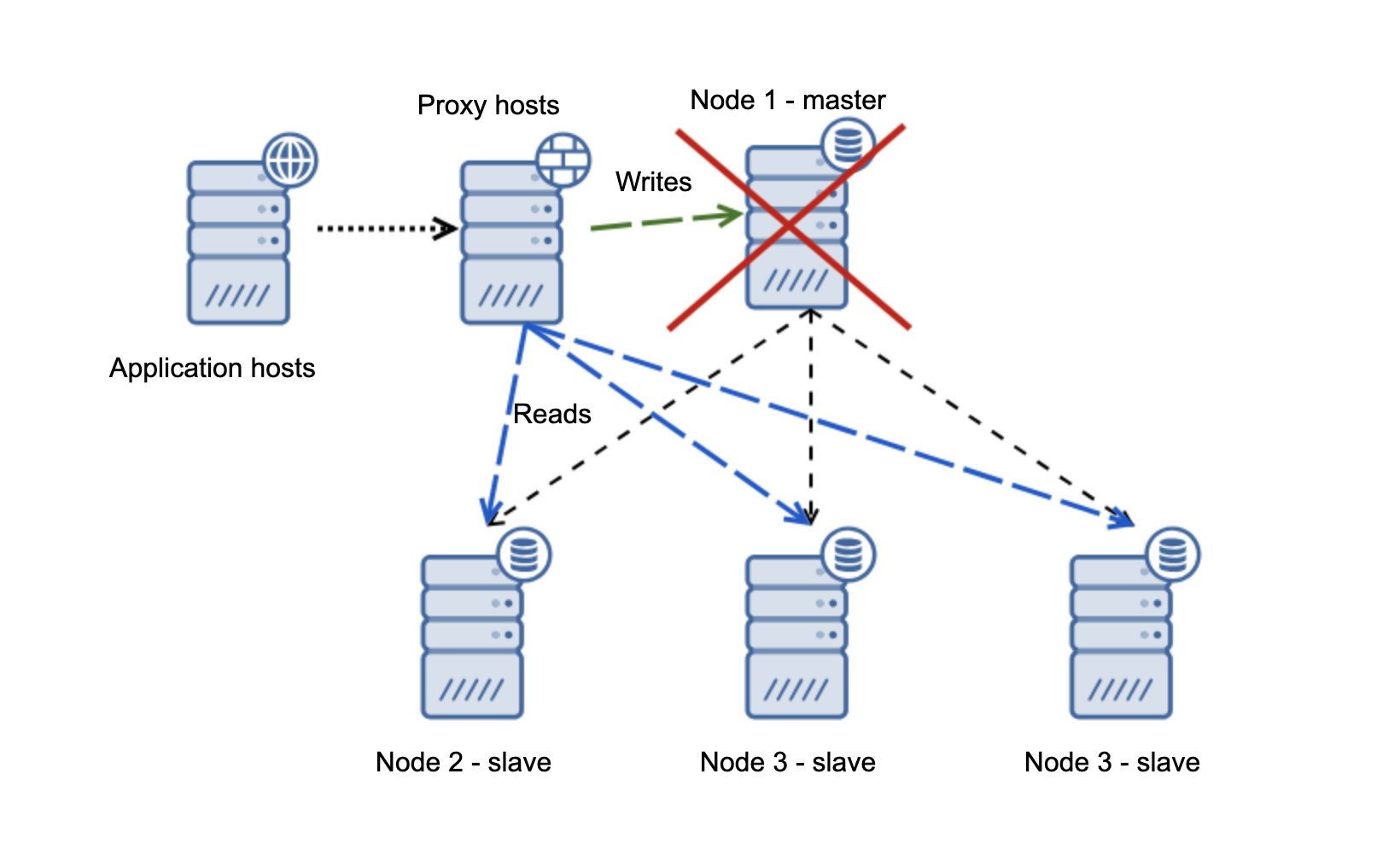
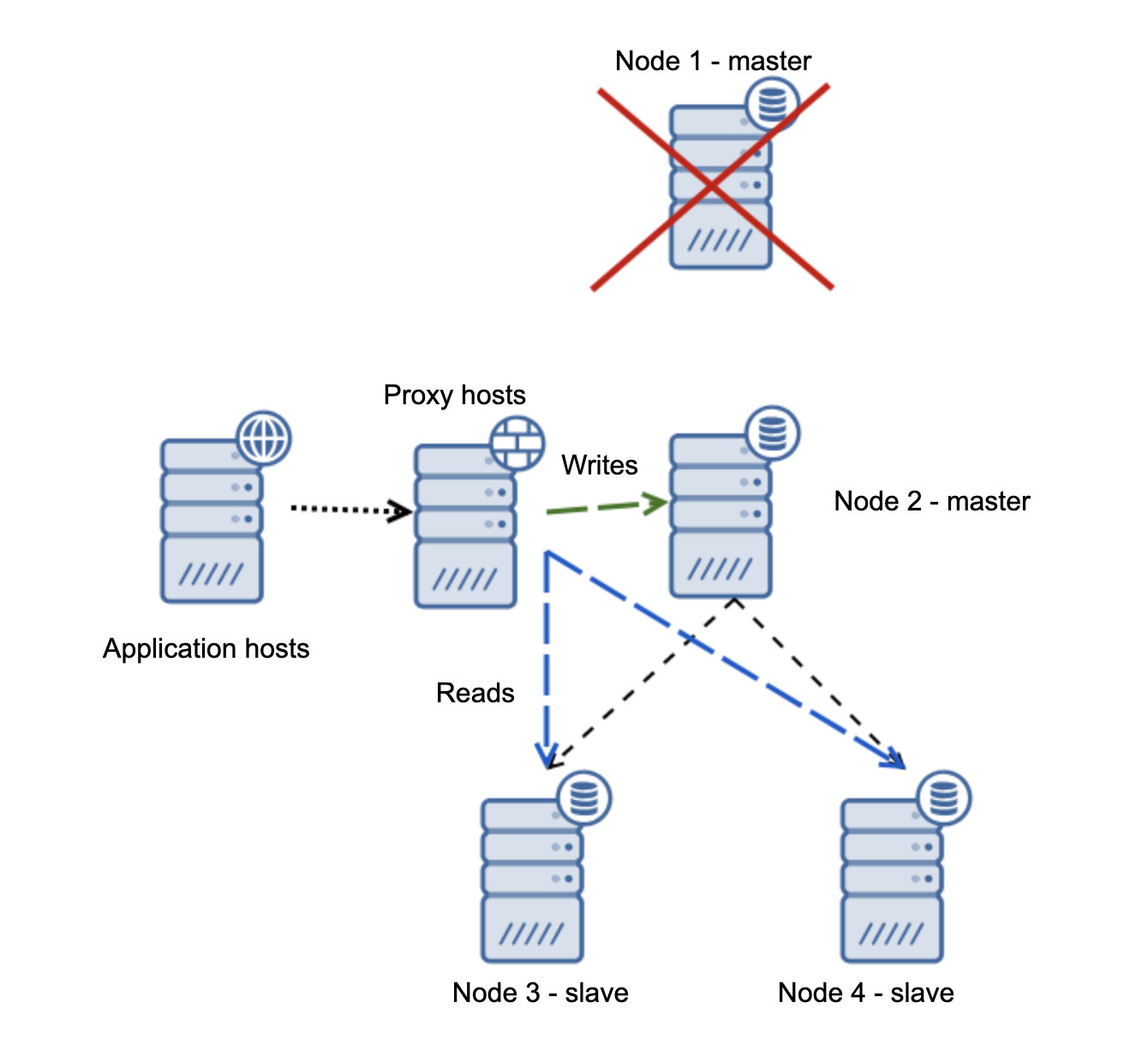
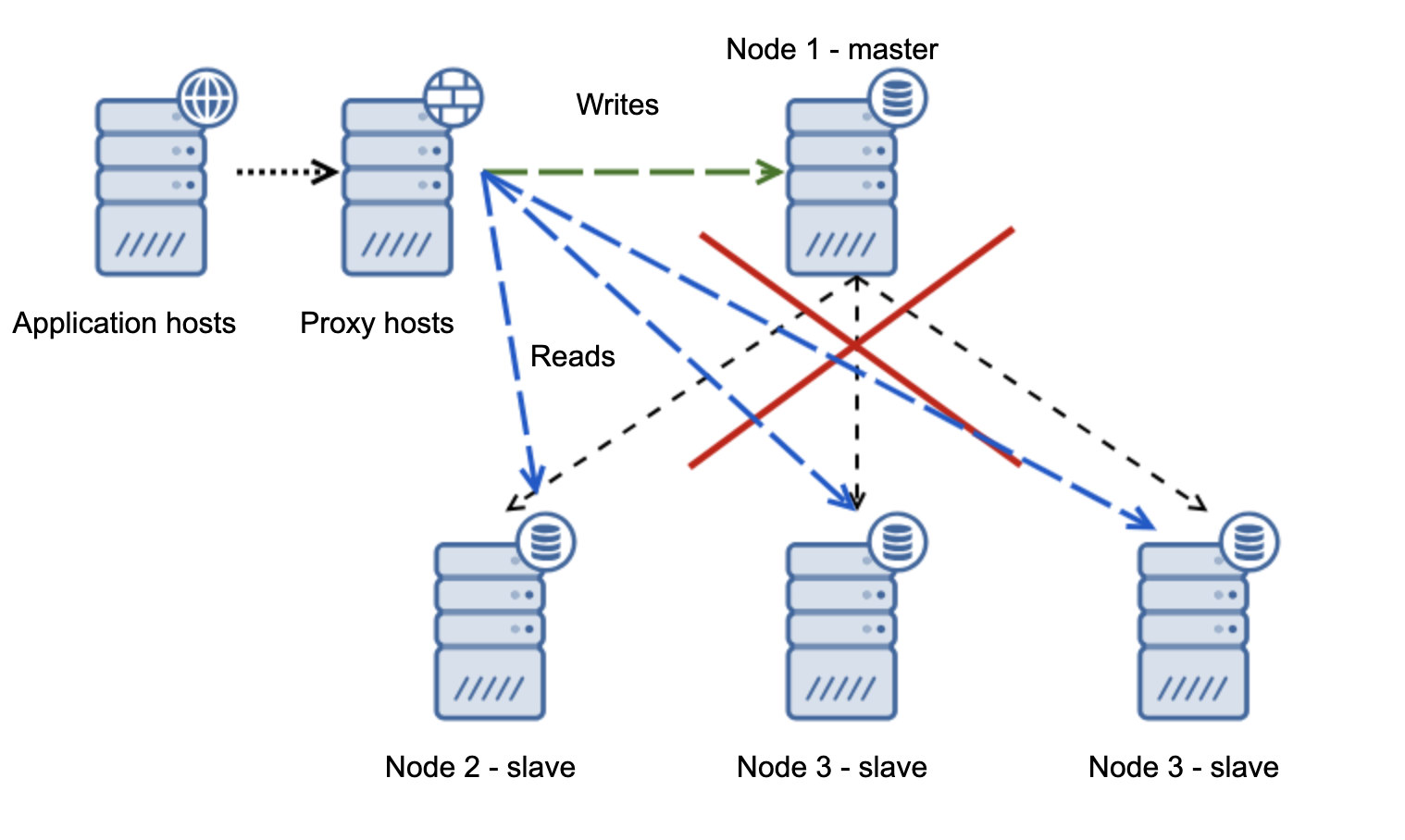
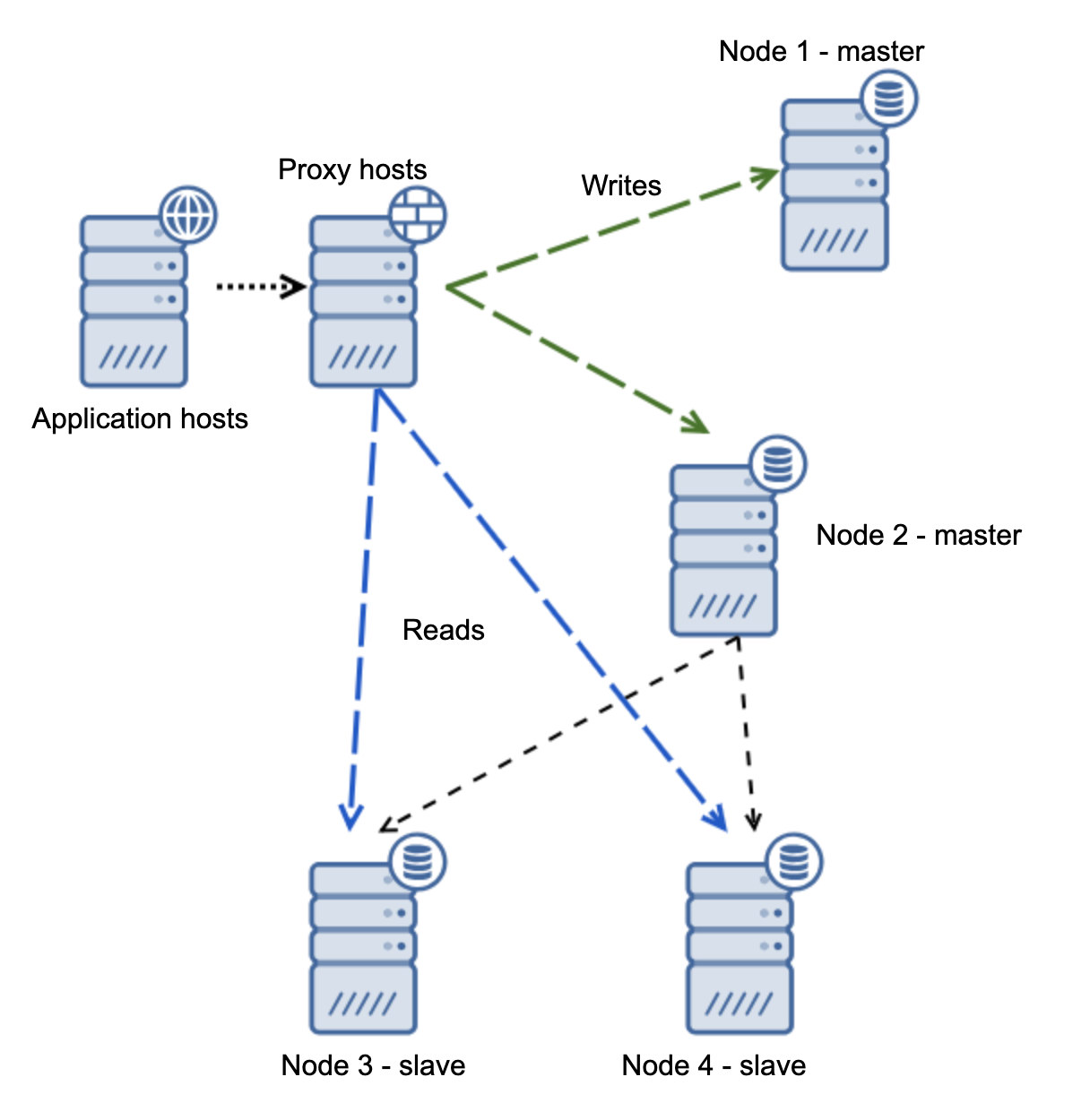
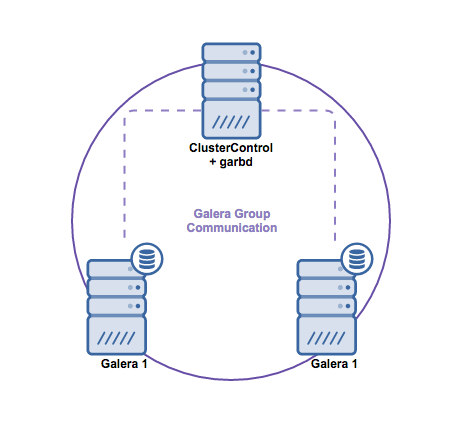
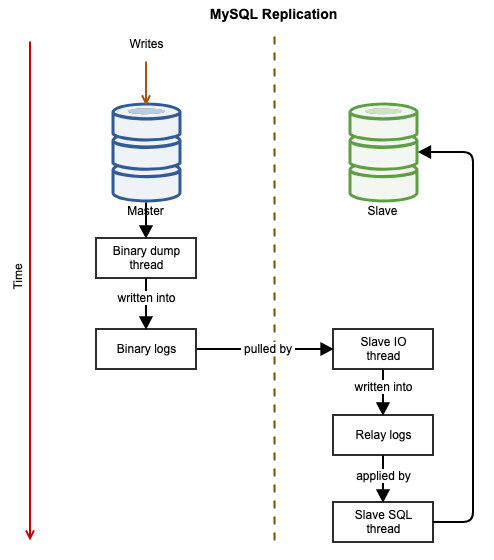
If you’re used to having an Oracle architecture having MAA (Maximum Available Architecture) with Data Guard ++ Oracle RAC (Real Application Cluster), same as MySQL/Percona Server, in MariaDB, you can choose from a synchronous replication, semi-sync, or an asynchronous replication.
For a highly available solution, MariaDB has Maxscale as your main option you can use. You can mix MaxScale with Keepalived and HAProxy. ClusterControl for example can manage this efficiently and even with the new arrival of MariaDB's product, MariaDB TX. See our previous blog to learn more on how ClusterControl can efficiently manage this.
With MariaDB being an open source technology, this question be considered: "How do we get support?"
You need to make sure when choosing a support option that it isn’t limited to the database but it should cover expertise in scalability, redundancy, resiliency, backups, high-availability, security, monitoring/observability, recovery and engaging on mission critical systems. Overall, the support offering you choose needs to come with an understanding of your architectural setup without exposing confidentiality of your data.
Additionally, MariaDB has a very large and collaborative community world wide. If you experience problems and want to ask people involved in this community, you can try on Freenode via IRC client (Internet Relay Chat), go to their community page, or join their mailing list.
Assessment or Preliminary Check
Backing up your data including configurations or setup files, kernel tunings, automation scripts need to be considered: it's an obvious task, but before you migrate, always secure everything first , especially when moving to a different platform.
You must assess as well that your applications are following up-to-date software engineering conventions and ensure that they are platform agnostic. These practices can be to your benefit especially when moving to a different database platform.
Since MariaDB is an open-source technology, make sure you know what the available connectors are that are available in MariaDB. This is pretty straight-forward right now as there are various available client-libraries. Check here for a list of these client libraries. Aside from that, you can check as well this list of available Clients and Utilities page.
Lastly, make sure of your hardware requirements.
MariaDB doesn't have specific requirements: a typical commodity server can work but that depends on how much performance you require. However, if you are engaged with ColumnStore for your analytical applications or data warehouse applications, check out their documentation. Taken from their page, for AWS, they have tested this generally using m4.4xlarge instance types as a cost effective middle ground. The R4.8xlarge has also been tested and performs about twice as fast for about twice the price.
What You Should Know
Same as MySQL, in MariaDB, you can create multiple databases whereas Oracle does not come with that same functionality.
In MariaDB, a schema is synonymous with a database. You can substitute the keyword SCHEMA instead of DATABASE in the MariaDB SQL syntax. For example, using CREATE SCHEMA instead of CREATE DATABASE; whilst Oracle has a distinction for this. A schema represents only a part of a database: the tables and other objects owned by a single user. Normally, there is a one-to-one relationship between the instance and the database.
For example, in a replication setup equivalent in Oracle (e.g. Real Application Clusters or RAC), you have your multiple instances accessing a single database. This lets you start Oracle on multiple servers, all accessing the same data. However, in MariaDB, you can allow access to multiple databases from your multiple instances and can even filter out which databases/schema you can replicate to a MariaDB node.
Referencing from one of our previous blogs (this and this), the same principle applies when speaking of converting your database with available tools found on the internet.
There is no such tool that can 100% convert Oracle database into MariaDB,though MariaDB has Red Rover Migration Practice ;this is a service that MariaDB offers and it's not free.
MariaDB talks about migration at Development Bank of Singapore (DBS), as a result of its collaboration with MariaDB on Oracle compatibility. It has been able to migrate more than 50 percent of its mission-critical applications in just 12 months from Oracle Database to MariaDB.
But if you are looking for some tools, sqlines tools, which are SQLines SQL Converter and SQLines Data Tool offer a simple yet operational set of tools.
The following sections below further outline the things that you must be aware of when it comes to migration and verifying the logical SQL result.
Data Type Mapping
MySQL and MariaDB share the same data types available. Although there are variations as to how it is implemented, you can check for the list of data types in MariaDB here.
While MySQL uses the JSON data-type, MariaDB differs as it's just an alias of LONGTEXT data type. MariaDB has also a function, JSON_VALID, which can be used within the CHECK constraint expression.
Hence, I'll make use of this tabular presentation below based on the information here, since data-types from MySQL against MariaDB don’t deviate so much, but I have added changes as the ROW data type has been introduced in MariaDB 10.3.0 as part of the PL/SQL compatibility feature.
Check out the table below:
| Oracle | MySQL |
|---|
| 1 | BFILE | Pointer to binary file, ⇐ 4G | VARCHAR(255) |
| 2 | BINARY_FLOAT | 32-bit floating-point number | FLOAT |
| 3 | BINARY_DOUBLE | 64-bit floating-point number | DOUBLE |
| 4 | BLOB | Binary large object, ⇐ 4G | LONGBLOB |
| 5 | CHAR(n), CHARACTER(n) | Fixed-length string, 1 ⇐ n ⇐ 255 | CHAR(n), CHARACTER(n) |
| 6 | CHAR(n), CHARACTER(n) | Fixed-length string, 256 ⇐ n ⇐ 2000 | VARCHAR(n) |
| 7 | CLOB | Character large object, ⇐ 4G | LONGTEXT |
| 8 | DATE | Date and time | DATETIME |
| 9 | DECIMAL(p,s), DEC(p,s) | Fixed-point number | DECIMAL(p,s), DEC(p,s) |
| 10 | DOUBLE PRECISION | Floating-point number | DOUBLE PRECISION |
| 11 | FLOAT(p) | Floating-point number | DOUBLE |
| 12 | INTEGER, INT | 38 digits integer | INT | DECIMAL(38) |
| 13 | INTERVAL YEAR(p) TO MONTH | Date interval | VARCHAR(30) |
| 14 | INTERVAL DAY(p) TO SECOND(s) | Day and time interval | VARCHAR(30) |
| 15 | LONG | Character data, ⇐ 2G | LONGTEXT |
| 16 | LONG RAW | Binary data, ⇐ 2G | LONGBLOB |
| 17 | NCHAR(n) | Fixed-length UTF-8 string, 1 ⇐ n ⇐ 255 | NCHAR(n) |
| 18 | NCHAR(n) | Fixed-length UTF-8 string, 256 ⇐ n ⇐ 2000 | NVARCHAR(n) |
| 19 | NCHAR VARYING(n) | Varying-length UTF-8 string, 1 ⇐ n ⇐ 4000 | NCHAR VARYING(n) |
| 20 | NCLOB | Variable-length Unicode string, ⇐ 4G | NVARCHAR(max) |
| 21 | NUMBER(p,0), NUMBER(p) | 8-bit integer, 1 <= p < 3 | TINYINT | (0 to 255) |
| 16-bit integer, 3 <= p < 5 | SMALLINT |
| 32-bit integer, 5 <= p < 9 | INT |
| 64-bit integer, 9 <= p < 19 | BIGINT |
| Fixed-point number, 19 <= p <= 38 | DECIMAL(p) |
| 22 | NUMBER(p,s) | Fixed-point number, s > 0 | DECIMAL(p,s) |
| 23 | NUMBER, NUMBER(*) | Floating-point number | DOUBLE |
| 24 | NUMERIC(p,s) | Fixed-point number | NUMERIC(p,s) |
| 25 | NVARCHAR2(n) | Variable-length UTF-8 string, 1 ⇐ n ⇐ 4000 | NVARCHAR(n) |
| 26 | RAW(n) | Variable-length binary string, 1 ⇐ n ⇐ 255 | BINARY(n) |
| 27 | RAW(n) | Variable-length binary string, 256 ⇐ n ⇐ 2000 | VARBINARY(n) |
| 28 | REAL | Floating-point number | DOUBLE |
| 29 | ROWID | Physical row address | CHAR(10)
Hence, for PL/SQL compatibility, you can use ROW (<field name> <data type> [{, <field name> <data type>}... ]) |
| 30 | SMALLINT | 38 digits integer | DECIMAL(38) |
| 31 | TIMESTAMP(p) | Date and time with fraction | DATETIME(p) |
| 32 | TIMESTAMP(p) WITH TIME ZONE | Date and time with fraction and time zone | DATETIME(p)![]() |
| 33 | UROWID(n) | Logical row addresses, 1 ⇐ n ⇐ 4000 | VARCHAR(n) |
| 34 | VARCHAR(n) | Variable-length string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) |
| 35 | VARCHAR2(n) | Variable-length string, 1 ⇐ n ⇐ 4000 | VARCHAR(n) |
| 36 | XMLTYPE | XML data | LONGTEXT |
Data type attributes and options:
| Oracle | MySQL |
|---|
| BYTE and CHAR column size semantics | Size is always in characters |
Transactions
MariaDB uses XtraDB from previous versions until 10.1 and shifted to InnoDB from version 10.2 onwards; though various storage engines can be an alternative choice for handling transactions such as the MyRocks storage engine.
By default, MariaDB has the autocommit variable set to ON which means that you have to explicitly handle transactional statements to take advantage of ROLLBACK for ignoring changes or taking advantage of using SAVEPOINT.
It's basically the same concept that Oracle uses in terms of commit, rollbacks and savepoints.
For explicit transactions, this means that you have to use the START TRANSACTION/BEGIN; <SQL STATEMENTS>; COMMIT; syntax.
Otherwise, if you have to disable autocommit, you have to explicitly COMMIT all the time for your statements that require changes to your data.
Dual Table
MariaDB has the dual compatibility with Oracle which is meant for compatibility of databases using a dummy table, namely DUAL. It operates just the same as MySQL where the FROM clause is not mandatory, so the DUAL table is not necessary. However, the DUAL table does not work exactly the same way as it does for Oracle, but for simple SELECT's in MariaDB, this is fine.
This suits Oracle's usage of DUAL so any existing statements in your application that use DUAL might require no changes upon migration to MariaDB.
The Oracle FROM clause is mandatory for every SELECT statement, so Oracle database uses DUAL table for SELECT statement where a table name is not required.
See the following example below:
In Oracle:
SQL> DESC DUAL;
Name Null? Type
----------------------------------------- -------- ----------------------------
DUMMY VARCHAR2(1)
SQL> SELECT CURRENT_TIMESTAMP FROM DUAL;
CURRENT_TIMESTAMP
---------------------------------------------------------------------------
16-FEB-19 04.16.18.910331 AM +08:00
But in MariaDB:
MariaDB [test]> DESC DUAL;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'DUAL' at line 1
MariaDB [test]> SELECT CURRENT_TIMESTAMP FROM DUAL;
+---------------------+
| CURRENT_TIMESTAMP |
+---------------------+
| 2019-02-27 04:11:01 |
+---------------------+
1 row in set (0.000 sec)
Note: the DESC DUAL syntax does not work in MariaDB and the results as well differ as CURRENT_TIMESTAMP (uses TIMESTAMP data type) in MySQL does not include the timezone.
SYSDATE
Oracle's SYSDATE function is almost the same in MariaDB.
MariaDB returns date and time and it’s a function that requires () (close and open parenthesis with no arguments required. To demonstrate this below, here's Oracle and MariaDB on using SYSDATE.
In Oracle, using plain SYSDATE just returns the date of the day without the time. But to get the time and date, use TO_CHAR to convert the date time into its desired format; whereas in MariaDB, you might not need it to get the date and the time as it returns both.
See example below.
In Oracle:
SQL> SELECT TO_CHAR (SYSDATE, 'MM-DD-YYYY HH24:MI:SS') "NOW" FROM DUAL;
NOW
-------------------
02-16-2019 04:39:00
SQL> SELECT SYSDATE FROM DUAL;
SYSDATE
---------
16-FEB-19
But in MariaDB:
MariaDB [test]> SELECT SYSDATE() FROM DUAL;
+---------------------+
| SYSDATE() |
+---------------------+
| 2019-02-27 04:11:57 |
+---------------------+
1 row in set (0.000 sec)
If you want to format the date, MariaDB has a DATE_FORMAT() function.
You can check the MariaDB's Date and Time documentation for more information.
Single Console for Your Entire Database Infrastructure
Find out what else is new in ClusterControl
TO_DATE
Oracle's TO_DATE equivalent in MariaDB is the STR_TO_DATE() function.
It’s almost identical to the one in Oracle: it returns the DATE data type, while in MariaDB it returns the DATETIME data type.
Oracle:
SQL> SELECT TO_DATE ('20190218121212','yyyymmddhh24miss') as "NOW" FROM DUAL;
NOW
-------------------------
18-FEB-19
MariaDB:
MariaDB [test]> SELECT STR_TO_DATE('2019-02-18 12:12:12','%Y-%m-%d %H:%i:%s') as "NOW" FROM DUAL;
+---------------------+
| NOW |
+---------------------+
| 2019-02-18 12:12:12 |
+---------------------+
1 row in set (0.000 sec)
SYNONYM
MariaDB does not have an equivalent functionality to this yet. Currently, based on their Jira ticket MDEV-16482 , this feature request to add SYNONYM is still open and no sign yet of progress as of this time. We're hoping that this will be incorporated in the future release. However, a possible alternative could be using VIEW.
Although SYNONYM in Oracle can be used to create an alias of a remote table,
e.g.
CREATE PUBLIC SYNONYM emp_table FOR hr.employees@remote.us.oracle.com
In MariaDB, you can take advantage of using the CONNECT storage engine which is more powerful than the FederatedX storage engine is, as it allows you to connect various database sources. You can check out this short video presentation.
There's a good example in the MariaDB's manual page,which I will not reiterate here as there are certain considerations you have to meet especially when using ODBC. Please refer to the manual.
Behaviour of Empty String and NULL
Take note that in MariaDB, empty string is not NULL whereas Oracle treats empty string as null values.
In Oracle:
SQL> SELECT CASE WHEN '' IS NULL THEN 'Yes' ELSE 'No' END AS "Null Eval" FROM dual;
Nul
---
Yes
In MariaDB:
MariaDB [test]> SELECT CASE WHEN '' IS NULL THEN 'Yes' ELSE 'No' END AS "Null Eval" FROM dual;
+-----------+
| Null Eval |
+-----------+
| No |
+-----------+
1 row in set (0.001 sec)
Sequences
Since MariaDB 10.3, Oracle-compatible sequences and a stored procedure language compliant with Oracle PL/SQL has been introduced. In MariaDB, creating a sequence is pretty similar to Oracle's SEQUENCE.
MariaDB's example:
CREATE SEQUENCE s START WITH 100 INCREMENT BY 10;
CREATE SEQUENCE s2 START WITH -100 INCREMENT BY -10;
and specifying workable minimum and maximum values shows as follows
CREATE SEQUENCE s3 START WITH -100 INCREMENT BY 10 MINVALUE=-100 MAXVALUE=1000;
Character String Functions
MariaDB, same as MySQL, also has a handful of string functions which is too long to discuss it here one-by-one. Hence, can check the documentation from here and compare this against Oracle's string functions.
DML Statements
Insert/Update/Delete statements from Oracle are congruous in MariaDB.
Oracle's INSERT ALL/INSERT FIRST is not supported in MariaDB and no one yet opened this feature request in their Jira (that I know of).
Otherwise, you’d need to state your MySQL queries one-by-one.
e.g.
In Oracle:
SQL> INSERT ALL
INTO CUSTOMERS (customer_id, customer_name, city) VALUES (1000, 'Jase Alagaban', 'Davao City')
INTO CUSTOMERS (customer_id, customer_name, city) VALUES (2000, 'Maximus Aleksandre Namuag', 'Davao City')
SELECT * FROM dual;
2 rows created.
But in MariaDB, you have to run the insert one at a time:
MariaDB [test]> INSERT INTO CUSTOMERS (customer_id, customer_name, city) VALUES (1000, 'Jase Alagaban', 'Davao City');
Query OK, 1 row affected (0.02 sec)
MariaDB [test]> INSERT INTO CUSTOMERS (customer_id, customer_name, city) VALUES (2000, 'Maximus Aleksandre Namuag', 'Davao City');
Query OK, 1 row affected (0.00 sec)
The INSERT ALL/INSERT FIRST doesn’t compare to how it is used in Oracle, where you can take advantage of conditions by adding a WHEN keyword in your syntax; there's no equivalent option as of this time in MariaDB.
Hence, your alternative solution on this is to use procedures.
Outer Joins "+" Symbol
Currently, for compatibility, it's not yet present in MariaDB. Hence, there are plenty of Jira tickets I have found in MariaDB but this one is much more precise in terms of feature request. Hence, your alternative choice for this time is to use JOIN syntax. Please check the documentation for more info about this.
START WITH..CONNECT BY
Oracle uses START WITH..CONNECT BY for hierarchical queries.
Starting MariaDB 10.2, they introduced CTE (Common Table Expression) which is designed to support generations of hierarchical data results, which use models such as adjacency lists or nested set models.
Similar to PostgreSQL and MySQL, MariaDB uses non-recursive and recursive CTE's.
For example, a simple non-recursive which is used to compare individuals against their group:
WITH sales_product_year AS (
SELECT product,
YEAR(ship_date) AS year,
SUM(price) AS total_amt
FROM item_sales
GROUP BY product, year
)
SELECT *
FROM sales_product_year S1
WHERE
total_amt >
(SELECT 0.1 * SUM(total_amt)
FROM sales_product_year S2
WHERE S2.year = S1.year)
while a recursive CTE (example: return the bus destinations with New York as the origin)
WITH RECURSIVE bus_dst as (
SELECT origin as dst FROM bus_routes WHERE origin='New York'
UNION
SELECT bus_routes.dst FROM bus_routes, bus_dst WHERE bus_dst.dst= bus_routes.origin
)
SELECT * FROM bus_dst;
PL/SQL in MariaDB?
Previously, in our blog about "Migrating from Oracle Database to MariaDB - What You Should Know", we showcased how powerful it is now in MariaDB adding its compliance to adopt PL/SQL as part of its database kernel. Whenever you use PL/SQL compatibility in MariaDB, make sure you have set SQL_MODE = 'Oracle' just like as follows:
SET SQL_MODE='ORACLE';
The new compatibility mode helps with the following syntax:
- Loop Syntax
- Variable Declaration
- Non-ANSI Stored Procedure Construct
- Cursor Syntax
- Stored Procedure Parameters
- Data Type Inheritance (%TYPE, %ROWTYPE)
- PL/SQL Style Exceptions
- Synonyms for Basic SQL Types (VARCHAR2, NUMBER, …)
For example, in Oracle, you can create a package, which is a schema object that groups logically related PL/SQL types, variables, and subprograms. Hence, in MariaDB, you can do it just like below:
MariaDB [test]> CREATE OR REPLACE PACKAGE BODY hello AS
->
-> vString VARCHAR2(255) := NULL;
->
-> -- was declared public in PACKAGE
-> PROCEDURE helloFromS9s(pString VARCHAR2) AS
-> BEGIN
-> SELECT 'Severalnines showing MariaDB Package Procedure in ' || pString || '!' INTO vString FROM dual;
-> SELECT vString;
-> END;
->
-> BEGIN
-> SELECT 'called only once per connection!';
-> END hello;
-> /
Query OK, 0 rows affected (0.021 sec)
MariaDB [test]>
MariaDB [test]> DECLARE
-> vString VARCHAR2(255) := NULL;
-> -- CONSTANT seems to be not supported yet by MariaDB
-> -- cString CONSTANT VARCHAR2(255) := 'anonymous block';
-> cString VARCHAR2(255) := 'anonymous block';
-> BEGIN
-> CALL hello.helloFromS9s(cString);
-> END;
-> /
+----------------------------------+
| called only once per connection! |
+----------------------------------+
| called only once per connection! |
+----------------------------------+
1 row in set (0.000 sec)
+--------------------------------------------------------------------+
| vString |
+--------------------------------------------------------------------+
| Severalnines showing MariaDB Package Procedure in anonymous block! |
+--------------------------------------------------------------------+
1 row in set (0.000 sec)
Query OK, 1 row affected (0.000 sec)
MariaDB [test]>
MariaDB [test]> DELIMITER ;
However, Oracle's PL/SQL is compiled before execution when it is loaded into the server. Although MariaDB does not say this in their manual, I would assume that the approach is the same as MySQL where it is compiled and stored in the cache when it's invoked.
Migration Tools
As my colleague Bart indicated in our previous blog here, sqlines tools which are SQLines SQL Converter and SQLines Data Tool can also provide aid as part of your migration.
MariaDB have their Red Rover Migration Practice service which you can take advantage of.
Overall, Oracle's migration to MariaDB is not as easy a thing as for migrating to MySQL/Percona, which could add more challenges than MariaDB; especially no PL/SQL compatibility exists in MySQL.
Anyhow, if you find or know of any tools that you find helpful and beneficial for migrating from Oracle to MariaDB, please leave a comment on this blog!
Testing
Same as what I have stated in this blog, allow me to reiterate some of it here.
As part of your migration plan, testing is a vital task that plays a very important role and affects your decision with regards to migration.
The tool dbdeployer (a replacement of MySQL Sandbox) is a very helpful tool that you can take advantage of. This is pretty easy for you to try and test different approaches and saves you time, rather than setting up the whole stack if your purpose is to try and test the RDBMS platform first.
For testing your SQL stored routines (functions or procedures), triggers, events, I suggest you use these tools mytap or the Google's Unit Testing Framework.
Percona tools can still be useful and can be incorporated to your DBA or engineering tasks even with MariaDB. Checkout Percona Toolkit here. You can cherry-pick the tools according to your needs especially for testing and production-usage tasks.
Overall, things that you need to keep-in-mind as your guidelines when doing a test for your MariaDB Server are:
- After your installation, you need to consider doing some tuning. Checkout our webinar about tuning your MariaDB server.
- Do some benchmarks and stress-load testing for your configuration setup on your current node. Checkout mysqlslap and sysbench which can help you with this. Also check out our blog "How to Benchmark Performance of MySQL & MariaDB using SysBench".
- Check your DDL's if they are correctly defined such as data-types, constraints, clustered and secondary indexes, or partitions, if you have any.
- Check your DML especially if syntax are correct and are saving the data correctly as expected.
- Check out your stored routines, events, trigger to ensure they run/return the expected results.
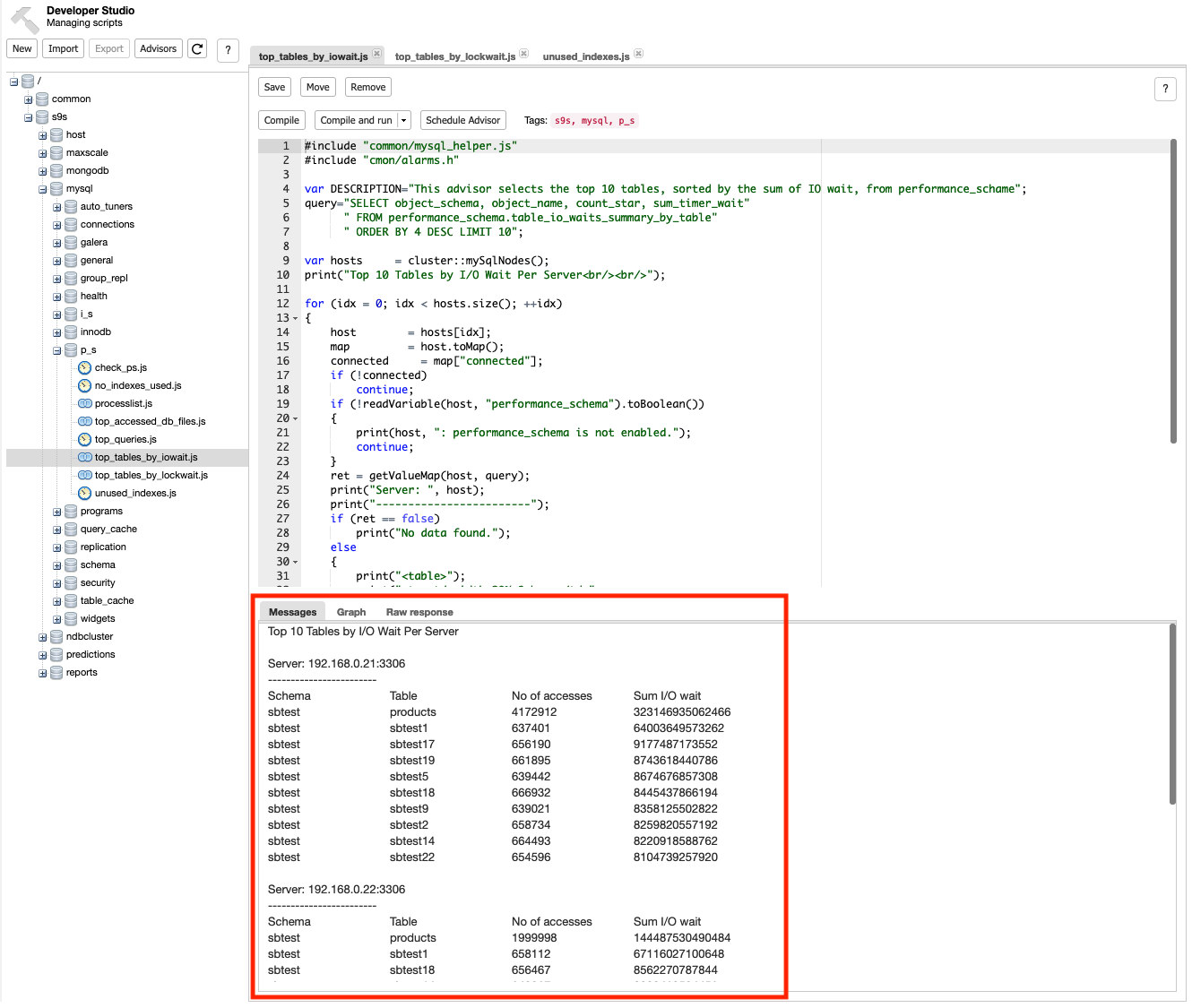
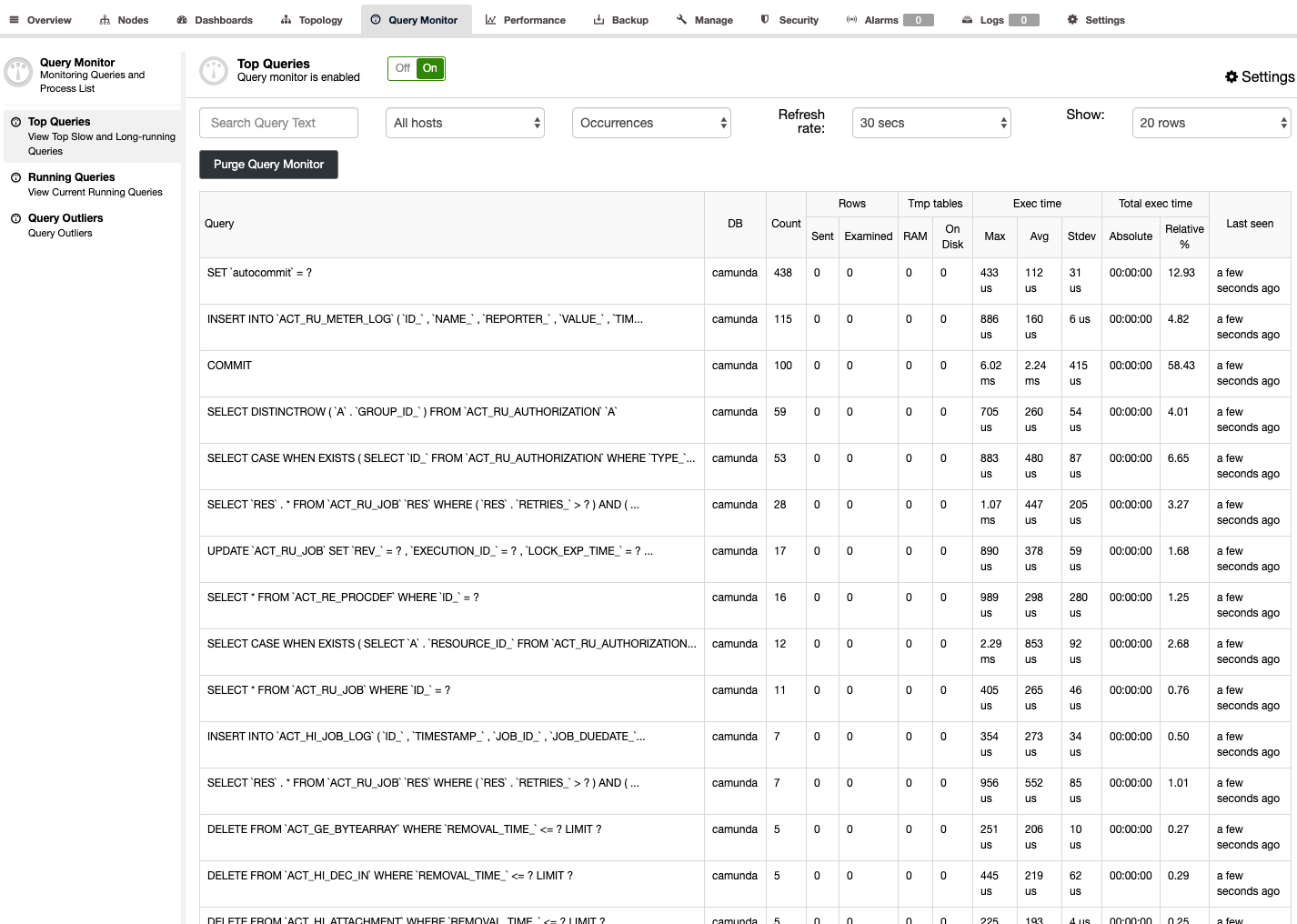
- Verify that your queries running are performant. I suggest you take advantage of open-source tools or try our ClusterControl product. It offers monitoring/observability especially of your MariaDB cluster. Check this previous blog in which we showcase how ClusterControl can help you manage MariaDB TX 3.0. You can use ClusterControl here to monitor your queries and its query plan to make sure they are performant.