Galera Cluster enforces strong data consistency, where all nodes in the cluster are tightly coupled. Although network segmentation is supported, replication performance is still bound by two factors:
- Round trip time (RTT) to the farthest node in the cluster from the originator node.
- The size of a writeset to be transferred and certified for conflict on the receiver node.
While there are ways to boost the performance of Galera, it is not possible to work around these 2 limiting factors.
Luckily, Galera Cluster was built on top of MySQL, which also comes with its built-in replication feature (duh!). Both Galera replication and MySQL replication exist in the same server software independently. We can make use of these technologies to work together, where all replication within a datacenter will be on Galera while inter-datacenter replication will be on standard MySQL Replication. The slave site can act as a hot-standby site, ready to serve data once the applications are redirected to the backup site. We covered this in a previous blog on MySQL architectures for disaster recovery.
In this blog post, we’ll see how straightforward it is to set up replication between two Galera Clusters (PXC 5.7). Then we’ll look at the more challenging part, that is, handling failures at both node and cluster levels. Failover and failback operations are crucial in order to preserve data integrity across the system.
Cluster Deployment
For the sake of our example, we’ll need at least two clusters and two sites - one for the primary and another one for the secondary. It works similarly to traditional MySQL master-slave replication, but on a bigger scale with three nodes in each site. With ClusterControl, you would achieve this by deploying two separate clusters, one on each site. Then, you would configure asynchronous replication between designed nodes from each cluster.
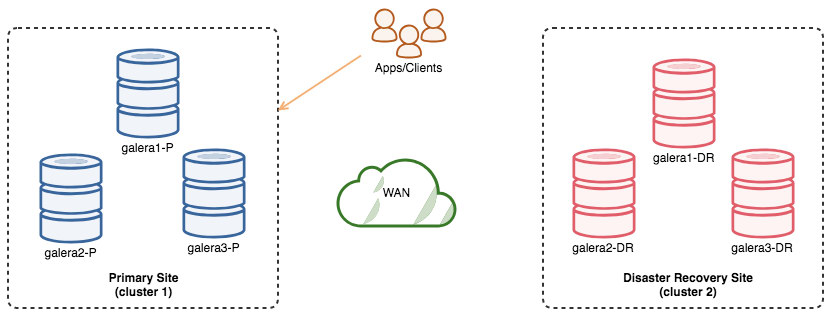
The following diagram illustrates our default architecture:

We have 6 nodes in total, 3 on the primary site and another 3 on the disaster recovery site. To simplify the node representation, we will use the following notations:
- Primary site: galera1-P, galera2-P, galera3-P (master)
- Disaster recovery site: galera1-DR, galera2-DR (slave), galera3-DR
Once the Galera Cluster is deployed, simply pick one node on each site to set up the asynchronous replication link. Take note that ALL Galera nodes must be configured with binary logging and log_slave_updates enabled. Enabling GTID is highly recommended, although not compulsory. On all nodes, configure with the following parameters inside my.cnf:
server_id=40 # this number must be different on every node.
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
expire_logs_days = 7If you are using ClusterControl, from the web interface, pick Nodes -> the chosen Galera node -> Enable Binary Logging. You might then have to change the server-id on the DR site manually to make sure every node is holding a distinct server-id value.
Then on galera3-P, create the replication user:
mysql> GRANT REPLICATION SLAVE ON *.* to slave@'%' IDENTIFIED BY 'slavepassword';On galera2-DR, point the slave to the current master, galera3-P:
mysql> CHANGE MASTER TO MASTER_HOST = 'galera3-primary', MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword' , MASTER_AUTO_POSITION=1;Start the replication slave on galera2-DR:
mysql> START SLAVE;From ClusterControl dashboard, once the replication is established, you should see the DR site has a slave and the Primary site got 3 masters (nodes that produce binary logs):
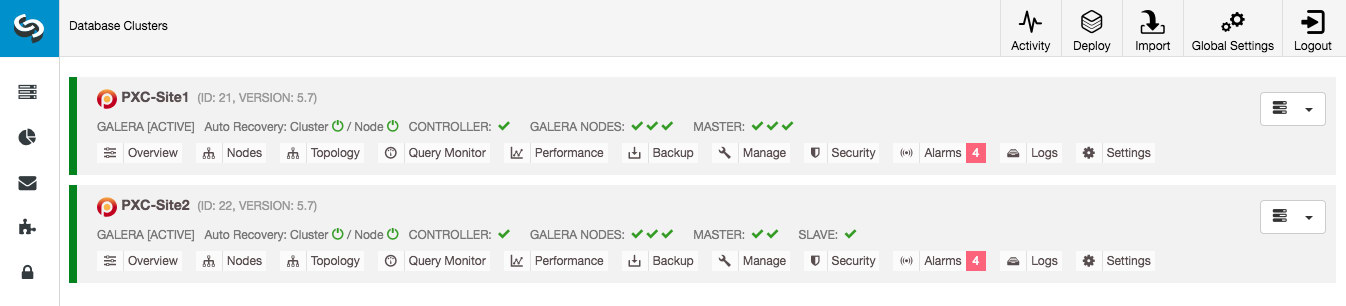
The deployment is now complete. Applications should send writes to the Primary Site only, as the replication direction goes from Primary Site to DR site. Reads can be sent to both sites, although the DR site might be lagging behind. Assuming that writes only reach the Primary Site, it should not be necessary to set the DR site to read-only (although it can be a good precaution).
This setup will make the primary and disaster recovery site independent of each other, loosely connected with asynchronous replication. One of the Galera nodes in the DR site will be a slave, that replicates from one of the Galera nodes (master) in the primary site. Ensure that both sites are producing binary logs with GTID, and that log_slave_updates is enabled - the updates that come from the asynchronous replication stream will be applied to the other nodes in the cluster.
We now have a system where a cluster failure on the primary site will not affect the backup site. Performance-wise, WAN latency will not impact updates on the active cluster. These are shipped asynchronously to the backup site.
As a side note, it’s also possible to have a dedicated slave instance as replication relay, instead of using one of the Galera nodes as slave.
Node Failover Procedure
In case the current master (galera3-P) fails and the remaining nodes in the Primary Site are still up, the slave on the Disaster Recovery site (galera2-DR) should be directed to any available masters, as shown in the following diagram:

With GTID-based replication, this is peanut. Simply run the following on galera2-DR:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = 'galera1-P', MASTER_AUTO_POSITION=1;
mysql> START SLAVE;Verify the slave status with:
mysql> SHOW SLAVE STATUS\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...
Retrieved_Gtid_Set: f66a6152-74d6-ee17-62b0-6117d2e643de:2043395-2047231
Executed_Gtid_Set: d551839f-74d6-ee17-78f8-c14bd8b1e4ed:1-4,
f66a6152-74d6-ee17-62b0-6117d2e643de:1-2047231
...Ensure the above values are reporting correctly. The executed GTID set should have 2 sets of GTID at this point, one from all transactions executed on the old master and the other for the new master.
Cluster Failover Procedure
If the primary cluster goes down, crashes, or simply loses connectivity from the application standpoint, the application can be directed to the DR site instantly. No database failover is necessary to continue the operation. If the application has connected to the DR site and starts to write, it is important to ensure no other writes are happening on the Primary Site once the DR site is activated.
The following diagram shows our architecture after application is failed over to the DR site:
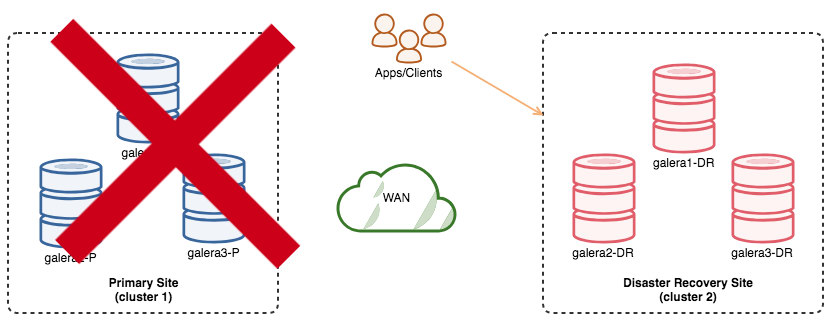
Assuming the Primary Site is still down, at this point, there is no replication between sites until we re-configure one of the nodes in the Primary Site once it comes back up.
For clean up purposes, the slave process on the DR site has to be stopped. On galera2-DR, stop replication slave:
mysql> STOP SLAVE;The failover to the DR site is now considered complete.
Cluster Failback Procedure
To failback to the Primary Site, one of the Galera nodes must become a slave to catch up on changes that happened on the DR site. The procedure would be something like the following:
- Pick one node to become a slave in the Primary Site (galera3-P).
- Stop all nodes other than the chosen one (galera1-P and galera2-P). Keep the chosen slave up (galera3-P).
- Create a backup from the new master (galera2-DR) in the DR site and transfer it over to the chosen slave (galera3-P).
- Restore the backup.
- Start the replication slave.
- Start the remaining Galera node in the Primary Site, with grastate.dat removed.
The below steps can then be performed to fail back the system to its original architecture - Primary is the master and DR is the slave.
1) Shut down all nodes other than the chosen slave:
$ systemctl stop mysql # galera1-P
$ systemctl stop mysql # galera2-POr from the ClusterControl interface, simply pick the node from the UI and click "Shutdown Node".
2) Pick a node in the DR site to be the new master (galera2-DR). Create a mysqldump backup with the necessary parameters (for PXC, pxc_strict_mode has to be set other than ENFORCING):
$ mysql -uroot -p -e 'set global pxc_strict_mode = "PERMISSIVE"'
$ mysqldump -uroot -p --all-databases --triggers --routines --events > dump.sql
$ mysql -uroot -p -e 'set global pxc_strict_mode = "ENFORCING"'3) Transfer the backup to the chosen slave, galera3-P via your preferred remote copy tool:
$ scp dump.sql galera3-primary:~4) In order to perform RESET MASTER on a Galera node, Galera replication plugin must be turned off. On galera3-P, disable Galera write-set replication temporarily and then restore the dump file in the very same session:
mysql> SET GLOBAL pxc_strict_mode = 'PERMISSIVE';
mysql> SET wsrep_on=OFF;
mysql> RESET MASTER;
mysql> SOURCE /root/dump.sql;Variable wsrep_on is a session variable. Therefore, we have to perform the restore operation within the same session using SOURCE statement. Otherwise, restoring using standard mysql client would require wsrep_on=OFF or commenting wsrep_provider inside my.cnf set during MySQL startup.
5) Start the replication thread on the chosen slave, galera3-P:
mysql> CHANGE MASTER TO MASTER_HOST = 'galera2-DR', MASTER_USER = 'slave', MASTER_PASSWORD = 'slavepassword', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;
mysql> SHOW SLAVE STATUS\G6) Start the remaining of the nodes in the cluster (one node at a time), and force an SST by removing grastate.dat beforehand:
$ rm -Rf /var/lib/mysql/grastate.dat
$ systemctl start mysqlOr from ClusterControl, simply pick the node -> Start Node -> check "Perform an Initial Start".
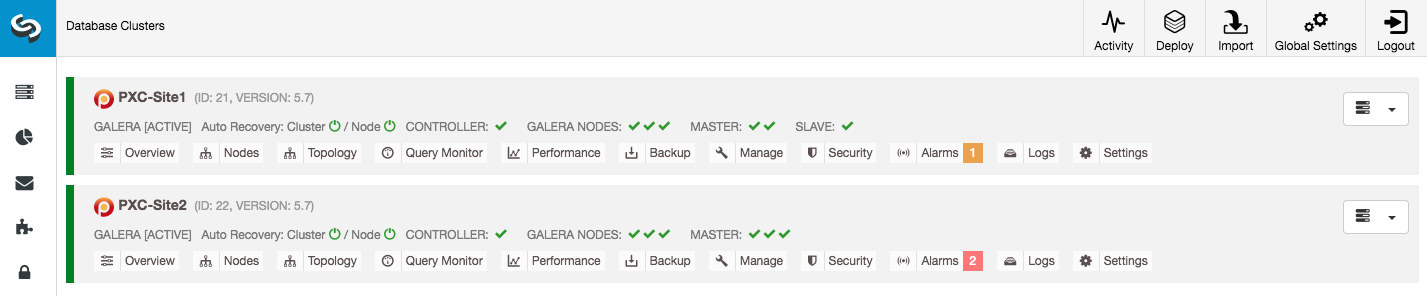
The above will force other Galera nodes to re-sync with galera3-P through SST and get the most up-to-date data. At this point, the replication direction has switched, from DR to Primary. Write operations are coming to the DR site and the Primary Site has become the replicating site:

From ClusterControl dashboard, you would notice the Primary Site has a slave configured while the DR site are all masters. In ClusterControl, MASTER indicator means all Galera nodes are generating binary logs:
7) Optionally, we can clean up slave's entries on galera2-DR since it's already become a master:
mysql> RESET SLAVE ALL;8) Once the Primary site catches up, we may switch the database traffic from application back to the primary cluster:
At this point, all writes must go to the Primary Site only. The replication link should be stopped as described under the "Cluster Failover Procedure" section above.
The above mentioned failback steps should be applied when staging back the DR site from the Primary Site:
- Stop replication between primary site and DR site.
- Re-slave one of the Galera nodes on the DR site to replicate from the Primary Site.
- Start replication between both sites.
Once done, the replication direction has gone back to its original configuration, from Primary to DR. Writes operations are coming to the Primary Site and the DR Site is now the replicating site:
Finally, perform some clean ups on the newly promoted master by running "RESET SLAVE ALL".
Advantages
Cluster-to-cluster asynchronous replication comes with a number of advantages:
- Minimal downtime during database failover operation. Basically, you can redirect the write almost instantly to the slave site, only and only if you can protect writes to not reach the master site (as these writes would not be replicated, and will probably be overwritten when re-syncing from the DR site).
- No performance impact on the primary site since it is independent from the backup (DR) site. Replication from master to slave is performed asynchronously. The master site generates binary logs, the slave site replicates the events and applies the events at some later time.
- Disaster recovery site can be used for other purposes, e.g., database backup, binary logs backup and reporting or heavy analytical queries (OLAP). Both sites can be used simultaneously, with exceptions on the replication lag and read-only operations on the slave side.
- The DR cluster could potentially run on smaller instances in a public cloud environment, as long as they can keep up with the primary cluster. The instances can be upgraded if needed. In certain scenarios, it can save you some costs.
- You only need one extra site for Disaster Recovery, as opposed to active-active Galera multi-site replication setup, which requires at least 3 sites to operate correctly.
Disadvantages
There are also drawbacks having this setup:
- There is a chance of missing some data during failover if the slave was behind, since replication is asynchronous. This could be improved with semi-synchronous and multi-threaded slaves replication, albeit there will be another set of challenges waiting (network overhead, replication gap, etc).
- Despite the failover operation being fairly simple, the failback operation can be tricky and prone to human error. It requires some expertise on switching master/slave role back to the primary site. It's recommended to keep the procedures documented, rehearse the failover/failback operation regularly and use accurate reporting and monitoring tools.
- There is no built-in failure detection and notification process. You may need to automate and send out notifications to the relevant person once the unwanted event occurs. One good way is to regularly check the slave's status from other available node's point-of-view on the master's site before raising an alarm for the operation team.
- Pretty costly, as you have to setup a similar number of nodes on the disaster recovery site. This is not black and white, as the cost justification usually comes from the requirements of your business. With some planning, it is possible to maximize usage of database resources at both sites, regardless of the database roles.